Spark pour les nuls – Partie 1 – Vue d’ensemble

Premier pas avec Apache Spark
Bienvenue dans cette série d’articles sur Apache Spark,
l’un des cadres de traitement de données volumineuses les plus utilisés. Nous verrons dans cet article quelques choses intéressantes sur Spark, de sa philosophie à l’installation sur votre machine.

Apache Spark est défini comme étant un moteur de calcul unifié et un ensemble de bibliothèques pour le traitement distribué des données sur un groupe d’ordinateurs, dans Spark, The définitif guide de Bill Chambers et Matei Zaharia.
Philosophie d’Apache Spark
Approfondissons les concepts de moteur de calcul unifié et de librairies. L’un des objectifs importants de Spark est d’offrir un moteur unifié pour le traitement distribué des données en réalisant différentes applications telles que le chargement de données, les requêtes SQL, l’apprentissage automatique et le streaming, en se concentrant sur le calcul des données, où qu’elles se trouvent.
Il fournit également de nombreuses librairies qui constituent la partie finale de ses composants : API pour les tâches courantes d’analyse de données. Spark SQL pour le traitement de données élémentaires, ML Lib pour l’apprentissage automatique, le traitement de flux et GraphX pour le traitement de graphes. Tous ceux-ci sont sur Apache Spark Core.
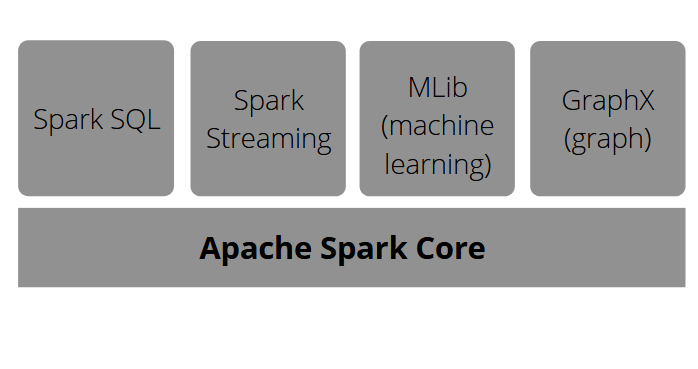
Le contexte de création d’Apache Spark
Avant 2005, les ordinateurs individuels étaient rendus de plus en plus rapides en augmentant la vitesse de leurs processeurs. Il est devenu difficile de fixer des limites strictes à la dissipation thermique. Ensuite, les développeurs de matériel ont développé le processus d’ajout de cœurs de processeurs parallèles ou distribués supplémentaires, ce qui a conduit à de nouveaux modèles comme apache Spark.
L’histoire d’Apache Spark
► En 2009 : Tout a commencé par le projet de recherche UC Berkeley. À cette époque, il n’y avait que Hadoop MapReduce, qui, pour plusieurs itérations, devait charger les données à partir de zéro plusieurs fois selon les besoins et écrire de nouvelles tâches distinctes, pour les algorithmes d’apprentissage automatique. Pour résoudre ce problème, l’équipe a eu l’idée de créer une programmation d’API fonctionnelle pour gérer des applications multi-étapes avec des données en mémoire.
La première version était destinée aux applications batch, une utilisation interactive pour les data scientists avec des requêtes scala et SQL.
Après celles-ci, ces librairies ont également été conçues : ML Lib, Streaming, GraphX sur le même moteur.
► En 2013 : Le projet prend de l’ampleur avec 100 contributeurs dans 30 organisations : Databricks est lancé.
► En 2014 : Version 1.0 Spark SQL pour les données intégrées
► En 2016 : Version 2.0 Streaming Structuré
Actuellement, Spark se développe rapidement et gagne en prix. De nombreuses entreprises ont commencé à l’utiliser (Uber, Netflix, NASA, CERN, …) pour différents cas d’usages.
Commentaire lancer Spark ?
Voyons ensuite commentez Spark sur votre ordinateur. Nous pouvons utiliser Spark avec Python, Java, Scala, R ou SQL. Spark lui-même est écrit en scala et exécuté sur JVM. Pour toute utilisation de l’API python, il faut un interpréteur python de 2.7. Pour R, nous avons besoin d’une version de R sur la machine.
Le lien de téléchargement officiel du projet : http://spark.apache.org/downloads.html
Spark pour le cluster hadoop, construction à partir de la source
Consoles interactives (ou shell)
Pour python pyspark : lancez .bin/pyspark et saisissez la commande spark
Pour spark shell(scala) : lancez .bin/spark-shell et entrez la commande spark
Pour spark sql (sql) : lancez .bin/spark-sql et saisissez la commande spark
Sur le cloud : utilisez l’édition communautaire de databricks (gratuite) créée par l’équipe de berkeley (scala, python, sql ou R).
Nous allons voir ensemble les différentes étapes pour installer Spark localement ou avec un IDE comme IntelliJ.

Installation locale de Spark
1. Télécharger et installer Java jdk 8 ou plus
Les jdk java les plus compatibles pour la dernière version de spark sont java 8 ou java 11.
Le lien pour le télécharger : https://www.oracle.com/java/technologies/downloads/#java8-windows
Il vous sera demandé de créer un compte oracle si vous n’en avez pas. Créez le compte et modifiez le fichier que vous avez téléchargé.
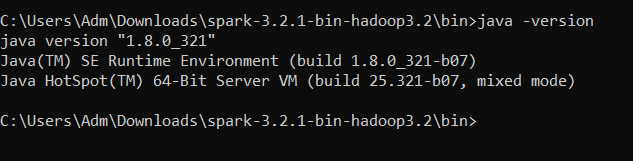
Après l’avoir installé, vous pouvez vérifier si tout va bien en vérifiant la version de Java que vous avez.
2. Télécharger et installer apache Spark
Le lien de téléchargement officiel du projet : http://spark.apache.org/downloads.html . Cliquez dessus pour télécharger la version Spark que vous souhaitez. Ici, nous avons choisi la version 3.2.1.
Vous devriez avoir ceci sur la page de téléchargement :
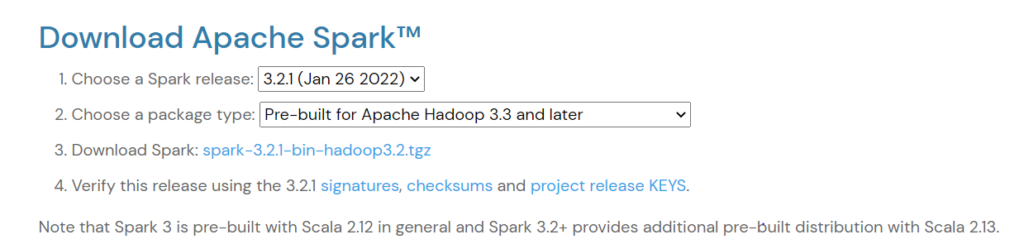
Cliquez sur Télécharger Spark. Le fichier sera téléchargé sur votre PC.
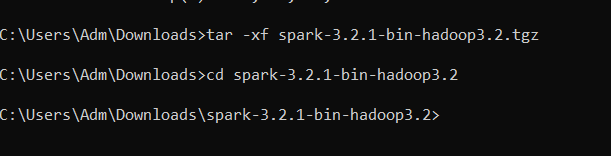
Tapez ensuite les commandes suivantes pour accéder au fichier zip.
3. Télécharger winutils.exe et hadoop.dll
Voici le lien pour télécharger le fichier winutils.exe et le fichier hadoop.dll : https://github.com/cdarlint/winutils/tree/master/hadoop-3.2.1
Créez un dossier hadoop_home dans le dossier C:/ de votre système. À l’intérieur de ce dossier, créez-en un autre bin nommé et placez les fichiers que vous avez téléchargés.
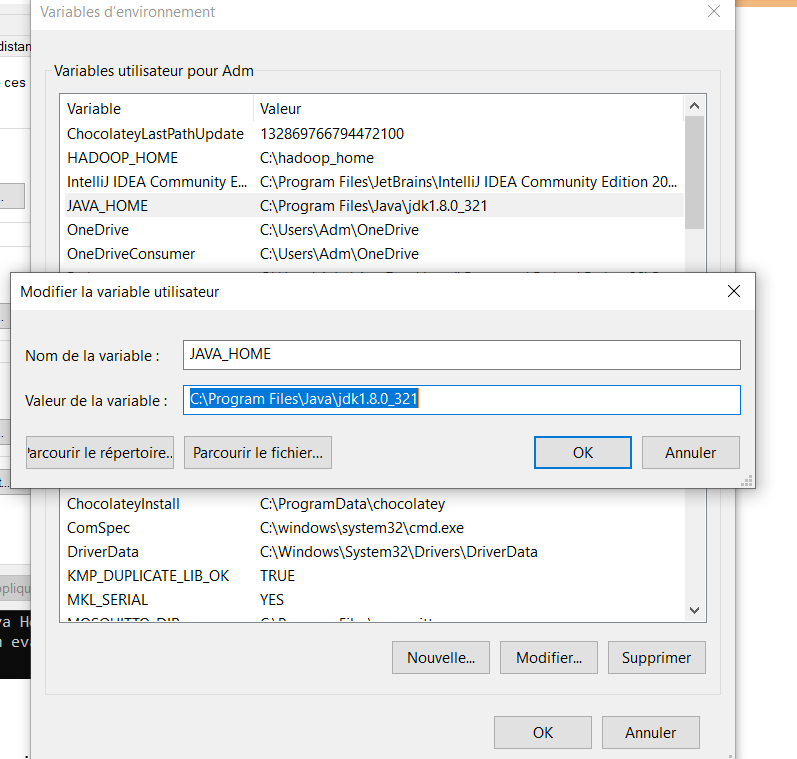
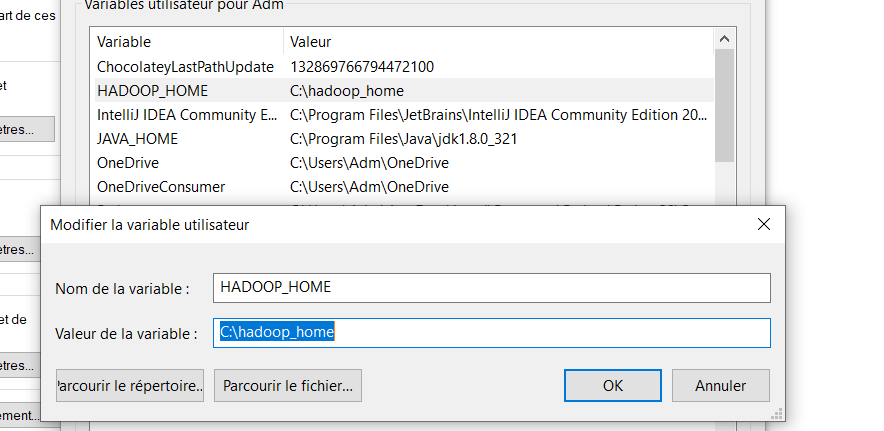
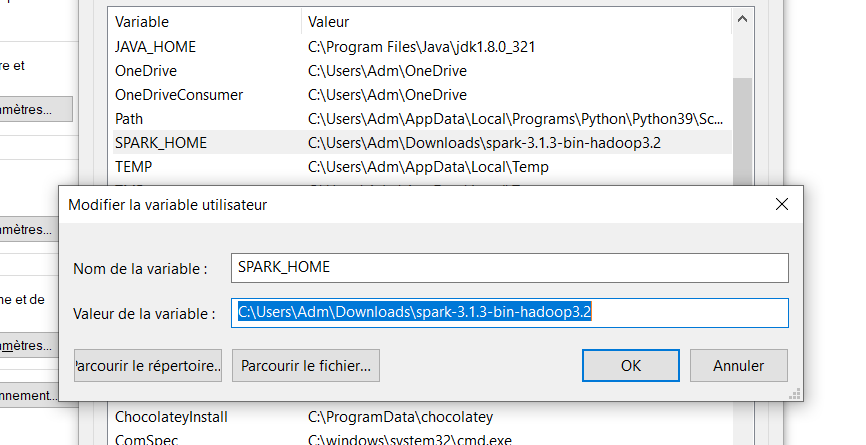
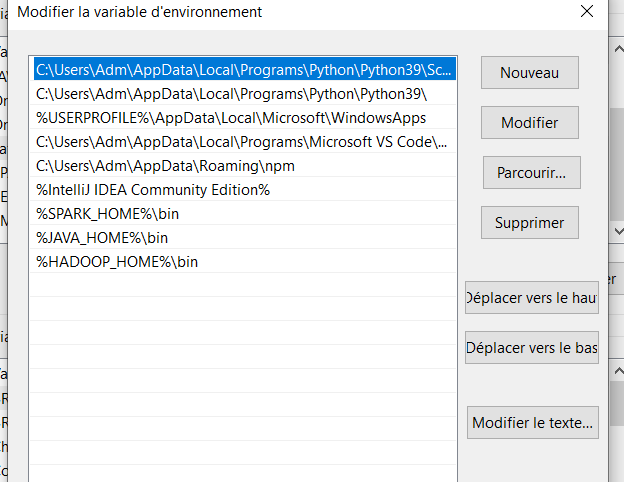
4. Définir les variables d’environnement
Créez les variables suivantes dans vos variables d’environnement et définissez les valeurs bin sur le chemin de Java, Spark et Hadoop installés.
JAVA_HOME est le chemin vers le JDK que vous avez installé ;
SPARK_HOME est le chemin d’accès au dossier Spark que vous avez téléchargé ;
HADOOP_HOME est le chemin vers le dossier hadoop_home que vous avez créé.
Vous devriez avoir quelque chose comme ça à la fin :
5. Lancer la ligne de commande spark
Ouvrez l’invitation de commande dans le dossier bin de votre spark home et lancez : spark-shell
Félicitations ! Vous avez maintenant Spark installé sur votre ordinateur.

Vous pouvez taper : spark dans l’invitation de commande pour voir si une session spark a été créée.

Installation de Spark avec IntelliJ
Vous pouvez également télécharger un IDE avec un plugin scala intégré et des librairies spark avec SBT.
SBT est un outil de construction pour la JVM, comme Maven ou Gradle. A partir d’un projet, il permet, entre autres, de gérer ses dépendances, de compiler, d’exécuter des tests et de publier des artefacts sur des dépôts.
Dans cet article, nous travaillerons avec IntelliJ en tant qu’IDE avec le plugin scala installé et la version spark 3.2.1.
Voici le lien pour télécharger la version communautaire d’IntelliJ pour le développement JVM : https://www.jetbrains.com/fr-fr/idea/download/#section=windows
Pour commencer à travailler avec Scala dans IntelliJ IDEA, vous devez télécharger et activer le plugin Scala. Si vous désactivez IntelliJ IDEA pour la première fois, vous pouvez installer le plug-in Scala lorsqu’IntelliJ IDEA suggère de télécharger les plug-ins proposés. Sinon, vous pouvez utiliser la page Paramètres -> Plugins pour l’installation.
Dans le prochain article, nous apprendrons l’architecture de Spark et les différentes parties.




