Le Deep Learning – Partie 2 – Apprentissage en profondeur

Comment peut-On optimiser un modèle CNN ?
Réussir à implémenter un modèle CNN passe obligatoirement par la compréhension du fonctionnement de l’algorithme et des paramètres à utiliser dans chacun de ses blocs. Dans l’article précédent, nous avons mis l’accent sur l’architecture et le fonctionnement de ce modèle. Dans cet article, nous expliquons les différents hyperparamètres.
Si vous débutez dans le domaine du Machine Learning et Deep Learning et que vous voulez implémenter des modèles dans ces technologies, il est recommandé de commencer par les algorithmes que vous maitrisez. En effet, les paramètres d’entrée d’un algorithme CNN étant complexes, il est préférable d’implémenter un modèle simple pour lequel vous connaissez la signification de chacun de ses hyperparamètres.
Nous avons vu dans l’article précédent que le choix de la structure du modèle est important, mais cela ne suffit pas : chaque couche nécessite l’initialisation de ses propres hyperparamètres.
Dans cet article, nous détaillerons les principaux hyperparamètres qui aiguillent le comportement d’un modèle CNN.
Dans l’apprentissage automatique et l’apprentissage profond, un hyperparamètre est un paramètre dont la valeur est utilisée pour le processus d’apprentissage. En revanche, les valeurs des autres paramètres (généralement la pondération des nœuds) sont acquises par apprentissage.
Les différents hyperparamètres varient en fonction de la nature des algorithmes d’apprentissage. Un réseau de neurones convolutif dispose de plusieurs hyperparamètres, dont parmi lesquels nous pouvons citer :
=> Une fonction d’activation :
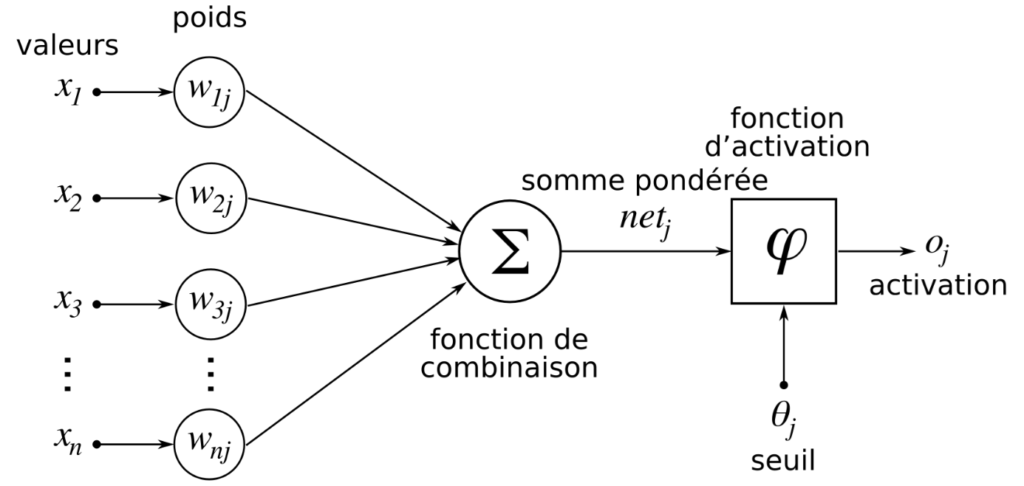
Ce premier hyperparamètre est responsable de l’activation des neurones : un neurone artificiel inspire son fonctionnement sur celui d’un neurone biologique. Ainsi, chaque neurone reçoit plusieurs entrées ayant chacune son propre poids de connexion, appelle aussi poids synaptique ou poids (w): un calcul s’effectue et permet d’obtenir en sortie une carte d’activation ou feature map qui indique où sont localisées les traits dans l’image. Plus la feature map est élevée, plus la portion de l’image balayée ressemble à la feature.
Plusieurs fonctions d’activation sont disponibles. Les plus utilisés sont :
• Relu
• Sigmoïde
• Softmax
• Tanh
L’utilisation de ces fonctions dépend du problème et du type de couche :
=> Dans un problème de classification d’images :
• La première couche de convolution utilise généralement la fonction d’activation ‘Relu’ qui consiste à mettre à zéro toutes les valeurs négatives.
• La dernière couche sert à donner le pourcentage d’appartenance de l’image à chaque classe : c’est la fonction d’activation ‘Softmax’ qui est généralement utilisée.
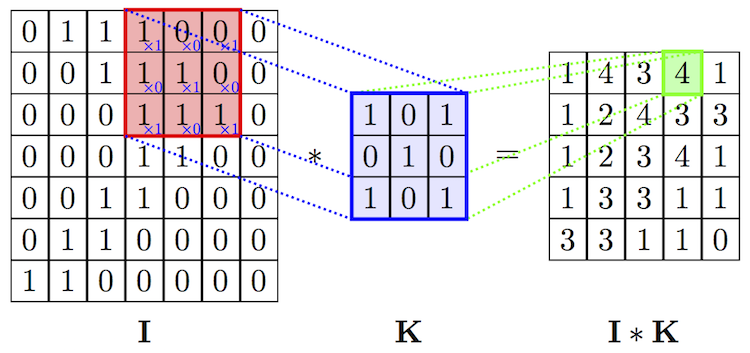
=> Pour une couche de convolution, il est nécessaire de passer les hyperparamètres suivants :
• Le nombre de filtres à appliquer
• La taille du noyau (kernel size) : c’est la taille du filtre à utiliser (exemple 3*3)
• Le pas (stride) : le pas avec lequel le filtre va se déplacer sur la totalité de l’image.
=> Parmi les autres hyperparamètres concernés par l’apprentissage du modèle :
• Batch Size : c’est le nombre d’images par lot envoyé au CNN lors de l’apprentissage.
• Epochs : c’est le nombre de fois où on envoie les images à la machine afin qu’elle apprenne. Attention : un nombre d’époques élevé peut conduire à un surapprentissage qui fera in fine baisser le taux de précision.
=> Après la phase de création de la structure du modèle, une phase de compilation sera faite et nécessitera l’initialisation de quelques hyperparamètres :
• Optimizer : c’est la fonction d’optimisation sur laquelle va se reposer le modèle pour l’optimisation de son résultat. ‘Adam’ est un exemple d’optimiseur connu.
• La Fonction de coût (perte) : cet hyperparamètre est utilisé lors de l’évaluation du modèle et permet de mesurer l’écart entre le résultat obtenu et le résultat souhaité.
• Précision : c’est l’un des hyperparamètres permettant d’évaluer un modèle CNN. Il représente le nombre d’images correctement classées.

Dans ce modèle nous obtenons :
- Un taux de précision égal à 0.88 qui correspond à 88% de bonnes réponses
- Une fonction coûte 0,3.
Dans cet article, nous avons présenté les principaux hyperparamètres qu’un data scientist doit connaître dans le cas où il souhaite implémenter un modèle CNN. Cette liste n’étant pas exhaustive, plusieurs autres hyperparamètres seront à découvrir et à maîtriser dans les prochains articles.


