Le Deep Learning – Partie 2 – Apprentissage en profondeur

How can we optimize a CNN model?
Successfully implementing a CNN model requires an understanding of how the algorithm works and the parameters to be used in each of its blocks. In the previous article, we focused on the architecture and the functioning of this model. In this article, we will explain the different hyperparameters.
If you are new to Machine Learning and Deep Learning and want to implement models in these technologies, it is recommended to start with the algorithms you know. Indeed, the input parameters of a CNN algorithm being complex, it is preferable to implement a simple model for which you know the meaning of each of its hyperparameters.
We have seen in the previous article that the choice of the model structure is important, but it is not enough : each layer requires the initialization of its own hyperparameters.
In this article, we will detail the main hyperparameters that steer the behavior of a CNN model.
In machine learning and deep learning, a hyperparameter is a parameter whose value is used in the learning process. In contrast, the values of the other parameters (usually the weighting of the nodes) are obtained by learning.
The different hyperparameters vary according to the nature of the learning algorithms. A convolutional neural network has several hyperparameters, among which we can mention :
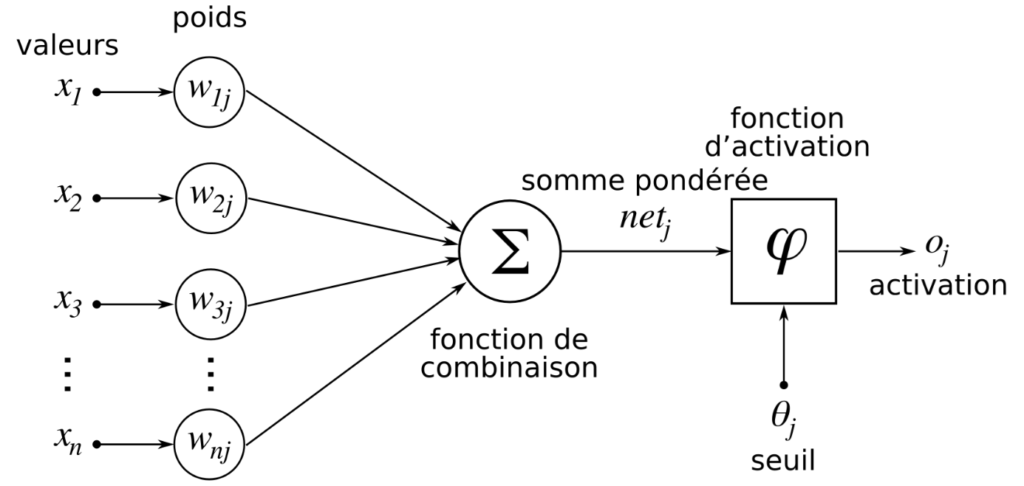
=> An activation function :
This first hyperparameter is responsible for the activation of the neurons: an artificial neuron inspires its functioning on that of a biological neuron. us, each neuron receives several inputs, each with its own connection weight, also called synaptic weight (w): a calculation is performed and allows to obtain an activation map or feature map which indicates where the features are located in the image. The higher the feature map, the more the portion of the image scanned looks like the feature.
Several activation functions are available. The most commonly used are:
• Relu
• Sigmoïde
• Softmax
• Tanh
The use of these functions depends on the problem and the type of layer :
=> In an image classification problem :
• The first convolution layer usually uses the ‘Relu’ activation function which consists in setting all negative values to zero.
• The last layer is used to give the percentage of the image belonging to each class : it is the activation function ‘Softmax’ which is generally used.
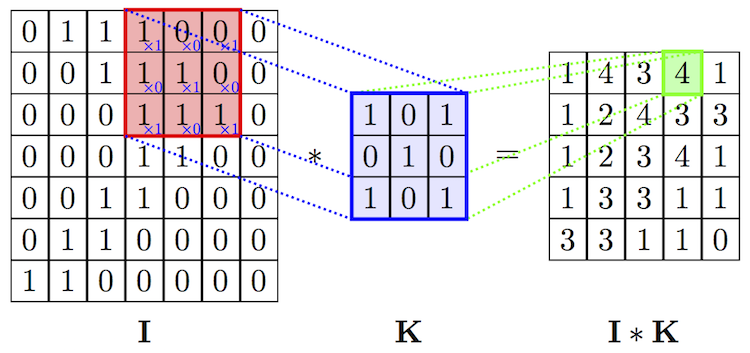
=> For a convolution layer, it is necessary to pass the following hyperparameters :
• The number of filters to apply
• The kernel size : this is the size of the filter to be used (example 3*3)
• Pitch (stride) : the pitch with which the filter will move over the entire image.
=> Other hyperparameters that affect model learning include :
• Batch Size : this is the number of images per batch sent to the CNN during training.
• Epochs : this is the number of times the images are sent to the machine so that it learns. Be careful: a high number of epochs can lead to overlearning which will ultimately lower the accuracy rate.
=> After the creation phase of the model structure, a compilation phase will be done and will require the initialization of some hyperparameters;:
• Optimizer : this is the optimization function on which the model will rely for the optimization of its result. ‘Adam’ is an example of a known optimizer.
• The cost function (loss) : this hyperparameter is used during the evaluation of the model and allows to measure the difference between the obtained result and the desired result.
• Accuracy : this is one of the hyperparameters used to evaluate a CNN model. It represents the number of correctly classified images.

In this model we obtain:
- A precision rate equal to 0.88 which corresponds to 88% of correct answers
- A cost function gives 0.3.
In this article, we have presented the main hyperparameters that a data scientist must know if he wants to implement a CNN model. This list is not exhaustive, several other hyperparameters will be discovered and mastered in future articles.

