Le Deep learning pour les débutants – Partie 1

Introduction
L’abondance des supers calculateurs accessibles notamment à travers le Cloud ainsi que l’accroissement des volumes de données générés par l’être humain via les équipements connectés (smartphones, objets connectés, …) ont conduit à une utilisation massive et à grande échelle des algorithmes de Machine Learning et Deep Learning.
Dans cet article, nous commencerons par présenter les grands principes de fonctionnement du Deep Learning.
Nous verrons ensuite l’architecture d’un réseau de neurones, puis terminerons par l’architecture d’un réseau de neurones convolutif.
Le Deep Learning ou l’apprentissage profond
Le Deep Learning est un cas particulier du Machine Learning : au lieu de développer un modèle de Machine Learning, nous développons des réseaux de neurones artificiels. Ainsi, nous donnons à la machine des données qui sont utilisées par un algorithme d’optimisation dans le but d’obtenir le meilleur modèle. Dans le cas du Deep Learning, le modèle est un réseau de fonctions connectées les unes aux autres, appelé réseau de neurones.
Historique
Le premier réseau de neurones artificiels fut inventé en 1943 par les deux mathématiciens américains Warren McCulloch et Walter Pitts et le neuropsychologue canadien Donald Hebb. Le développement de ce programme fut directement inspiré du fonctionnement du neurone biologique.
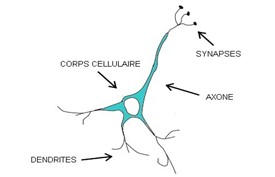
Les neurones biologiques sont excitables et connectés les uns aux autres.
Leur rôle est de transmettre des informations au travers de notre système nerveux.
Chaque neurone est composé de plusieurs dendrites, un corps cellulaire et un axone : les dendrites sont la porte d’entrée d’un neurone, et c’est au niveau des synapses que le neurone reçoit des signaux provenant du neurone qui le précède.
Ces signaux peuvent être de type excitateur ou inhibiteur : lorsque la somme de ces signaux dépasse un certain seuil, le neurone s’active et produit un signal électrique. Ce signal circule le long de l’axone en direction des terminaisons pour être envoyé à son tour vers d’autres neurones de notre système nerveux.
Les neurones artificiels furent donc conçus en remplaçant le corps cellulaire par une fonction d’activation qui prend plusieurs entrées et qui génère une sortie.
L’architecture d’un réseau de neurones artificiel
Un réseau de neurones est un ensemble de neurones disposés en réseau.
Ces neurones sont organisés principalement en trois types de couches qui sont reliées entre elles par des connexions appelées des poids :
• La couche d’entrée (Input layer) : c’est la première couche dans un réseau de neurones et qui consiste à lire les données brutes et l’aplatir sous forme d’un vecteur. Chaque donnée au sein de ce vecteur sera représentée par un neurone.
• La couche cachée (Hidden Layer) : c’est le cœur du réseau. Chaque neurone de cette couche va recevoir les valeurs de différents neurones de la couche précédente avec les poids qui leurs correspond et en utilisant une fonction d’activation : la décision sera alors prise d’activer ce neurone ou non.
• La couche de sortie (Output Layer) : c’est la dernière couche d’un réseau de neurones. Elle va contenir le résultat final. Une fois ce résultat calculé, il va être accompagné par le calcul de la fonction coût (ou la fonction perte) qui mesure l’erreur entre le résultat trouvé et le résultat souhaité.
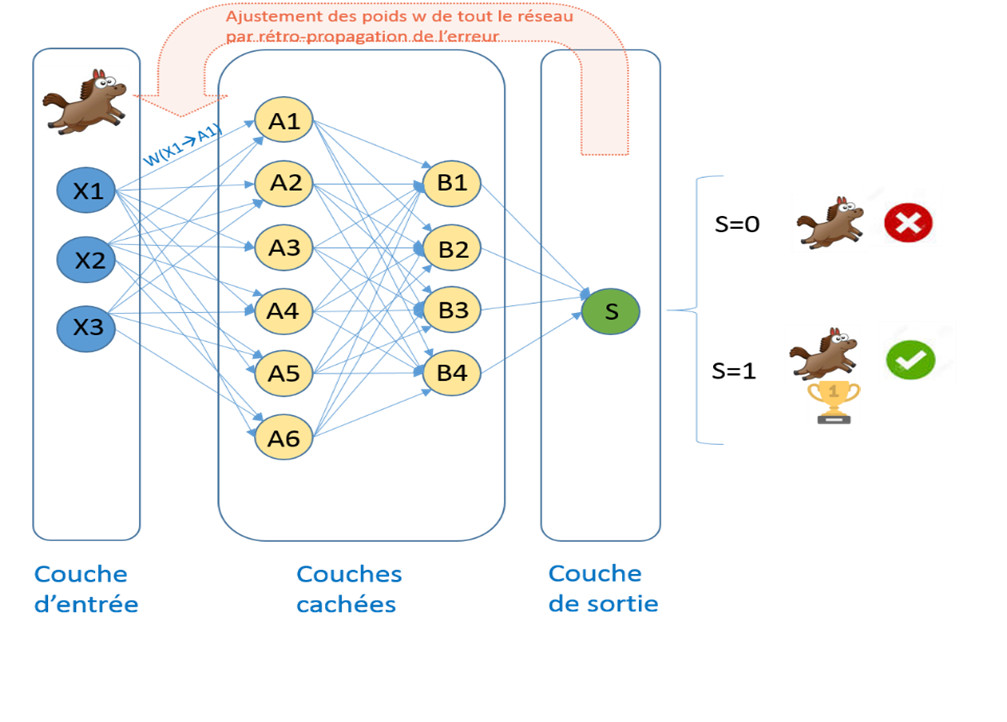
Si l’on prend l’exemple illustré par la figure ci-dessous, nous disposons d’un réseau de neurones qui a pour but de prédire si l’image passée en entrée illustre un cheval ou pas.
Dans notre cas notre réseau de neurones est composé de :
- Une couche d’entrée : chaque neurone de cette couche contient un pixel de l’image
- Deux couches cachées qui seront entrainées pour prédire le résultat souhaité
- Une couche de sortie qui va contenir le résultat prédit : la valeur 1 pour indiquer que l’image illustre bien un cheval, la valeur 0 sinon.
Présentation et architecture d’un réseau de neurones convolutif : CNN
Les réseaux de neurones convolutifs sont une variante améliorée des réseaux de neurones classiques et sont utilisés essentiellement pour la classification d’images.
Un réseau de neurones convolutif est composé de deux blocs :
• Le premier bloc, spécifique au CNN, sert à l’extraction des caractéristiques (features en anglais) d’une image
• Le deuxième bloc est un réseau de neurones classique tel que décrit ci-dessus, et utilise la sortie du premier bloc
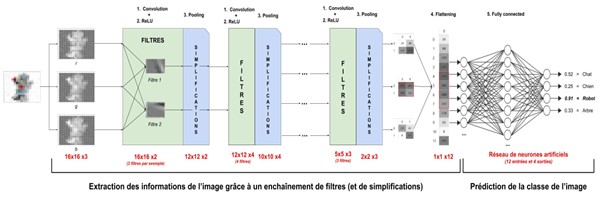
La figure ci-dessus met en évidence ces deux blocs
Le deuxième bloc, étant un réseau de neurones classique, a été présenté dans le premier paragraphe.
Voyons donc plus en détail le premier bloc, qui est composé :
• Des couches de convolutions : un réseau de neurones convolutifs commence nécessairement par une couche de convolutions. Chacune de ces couches prend en entrée un bloc d’images sur lequel elle va appliquer des filtres de convolution. Le principe d’un tel filtre est de faire passer un noyau (Kernel en anglais) sur l’intégralité de l’image avec un pas (stride en anglais) et des dimensions qui seront choisies par le data scientist dans le but d’extraire les informations pertinentes de l’image. Plusieurs filtres successifs seront appliqués sur une image pour donner un résultat en plusieurs images appelées cartes de convolutions.
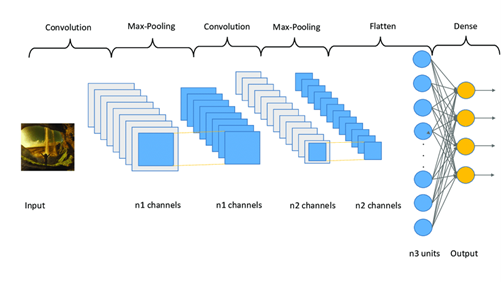
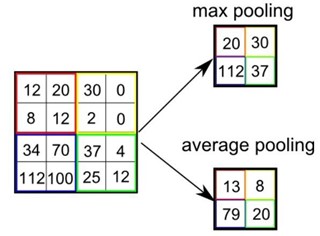
• La couche de Pooling : une couche de convolution est accompagnée généralement par une couche de Pooling. Cette couche réduit la taille de l’image en appliquant des fonctions de deux types : AVG pooling (average, qui consiste à retourner la moyenne) et Max pooling (qui consiste à retourner le maximum). Le plus populaire est le Max pooling et son principe est de diviser l’image en des blocs égaux : les valeurs maximales de chaque bloc vont construire la nouvelle image.
L’image ci-dessous présente les deux types de pooling :
A la fin de tout ce processus, nous obtenons un pipeline composé :
• du premier bloc permettant d’extraire les caractéristiques des images
• du deuxième bloc qui s’occupera d’effectuer la classification.
Conclusion
Dans cet article, nous avons vu le fonctionnement et l’architecture d’un réseau de neurones classique ainsi que celui d’un réseau de neurones convolutif et ses spécificités par rapport à un réseau de neurones entièrement connectés.
Comprendre le fonctionnement des réseaux de neurones est une phase essentielle pour l’implémentation d’un bon modèle, mais n’est pas suffisant.
Nous verrons dans le prochain article, comment optimiser un CNN en détaillant ses hyperparamètres.


