Le Deep learning pour les débutants – Partie 1

Introduction
The abundance of supercomputers accessible through the Cloud as well as the increase in the volume of data generated by humans via connected devices (smartphones, connected objects, …) have led to a massive and large-scale use of Machine Learning and Deep Learning algorithms.
In this article, we will start by presenting the main principles of Deep Learning.
We will then look at the architecture of a neural network, and we will finish with the architecture of a convolutional neural network.
Le Deep Learning
Deep Learning is a special case of Machine Learning: instead of developing a Machine Learning model, we develop artificial neural networks. Thus, we give the machine data that are used by an optimization algorithm in order to obtain the best model. In the case of Deep Learning, the model is a network of functions connected to each other, called neural network.
History
The first artificial neural network was invented in 1943 by the two American mathematicians Warren McCulloch and Walter Pitts and the Canadian neuropsychologist Donald Hebb. The development of this program was directly inspired by the functioning of the biological neuron.
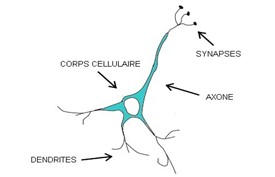
Biological neurons are excitable and connected to each other.
Their role is to transmit information through our nervous system.
Each neuron is composed of several dendrites, a cell body and an axon: the dendrites are the gateway to a neuron, and it is at the synapses that the neuron receives signals from the preceding neuron.
These signals can be excitatory or inhibitory: when the sum of these signals exceeds a certain threshold, the neuron is activated and produces an electrical signal. This signal travels along the axon towards the endings to be sent in turn to other neurons in our nervous system.
Artificial neurons were therefore designed by replacing the cell body with an activation function that takes several inputs and generates an output.
The architecture of an artificial neural network
A neural network is a set of neurons arranged in a network.
These neurons are organized mainly into three types of layers that are linked together by connections called weights:
• The input layer: this is the first layer in a neural network and consists of reading the raw data and flattening it into a vector. Each data within this vector will be represented by a neuron.
• The Hidden Layer : this is the heart of the network. Each neuron of this layer will receive the values of different neurons of the previous layer with the weights that correspond to them and using an activation function: the decision will then be taken to activate this neuron or not.
• The Output Layer: this is the last layer of a neural network. It will contain the final result. Once this result is calculated, it will be accompanied by the calculation of the cost function (or the loss function) which measures the error between the result found and the desired result.
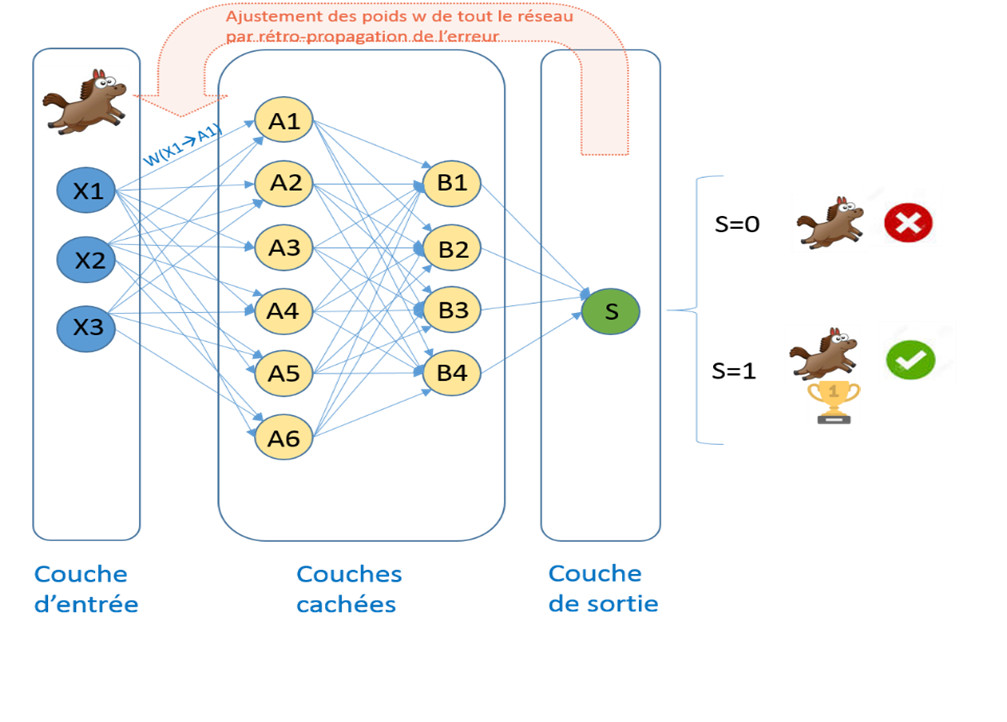
If we take the example shown in the figure below, we have a neural network that aims to predict whether the input image shows a horse or not.
In our case our neural network is composed of :
- An input layer: each neuron of this layer contains a pixel of the image
- Two hidden layers that will be trained to predict the desired result
- An output layer that will contain the predicted result: the value 1 to indicate that the image shows a horse, the value 0 otherwise.
Presentation and architecture of a convolutional neural network : CNN
Convolutional neural networks are an improved variant of classical neural networks and are mainly used for image classification.
A convolutional neural network is composed of two blocks:
• The first block, specific to the CNN, is used to extract the features of an image
• The second block is a classical neural network as described above, and uses the output of the first block
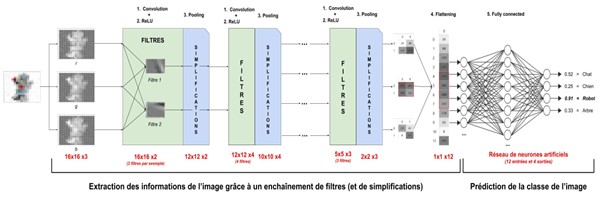
The figure above highlights these two blocks
The second block, being a classical neural network, has been discussed in the first paragraph.
Let’s have a closer look at the first block, which is composed of :
• Convolution layers : a convolutional neural network necessarily starts with a convolution layer. Each of these layers takes as input a block of images on which it will apply convolution filters. The principle of such a filter is to pass a kernel over the entire image with a step (stride) and dimensions that will be chosen by the data scientist in order to extract relevant information from the image. Several successive filters will be applied to an image to give several images called convolution maps.
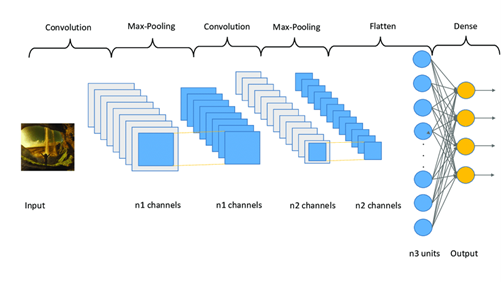
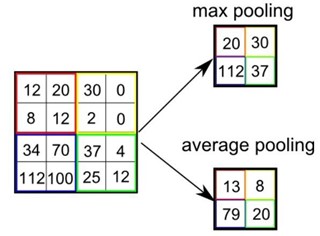
• The pooling layer: a convolution layer is usually accompanied by a pooling layer. This layer reduces the size of the image by applying functions of two types: AVG pooling (average, which consists in returning the average) and Max pooling (which consists in returning the maximum). The most popular is Max pooling and its principle is to divide the image into equal blocks: the maximum values of each block will build the new image.
The image below shows the two types of pooling:
At the end of this process, we obtain a pipeline composed of:
• the first block which extracts the characteristics of the images
• the second block which will perform the classification.
Conclusion
In this article, we have seen the functioning and architecture of a classical neural network as well as that of a convolutional neural network and its specificities compared to a fully connected neural network.
Understanding how neural networks work is an essential step in implementing a good model, but it is not enough.
We will see in the next article, how to optimize a CNN by detailing its hyperparameters.