Apache Spark - Part 3 - Overview

Spark is a simple, fast framework with libraries that help with accurate analysis of large data sets in multiple languages.
We will have in this article an overview of these tools.
We briefly describe what each of them is for and how to use it.

Running an application in production
Spark allows us to easily create applications in production with the command: spark-submit.
It allows us to send our application to a cluster, launch it there and run it.
Here is an example to illustrate this with a scala application available in the Spark installation folder.
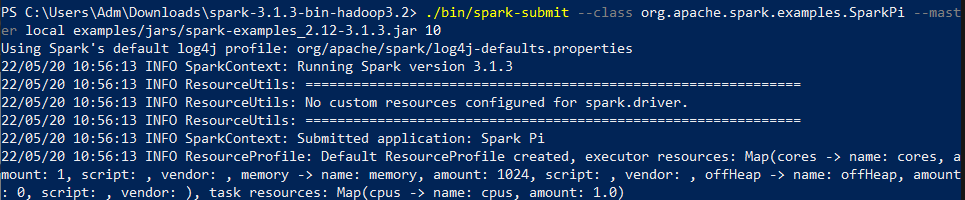
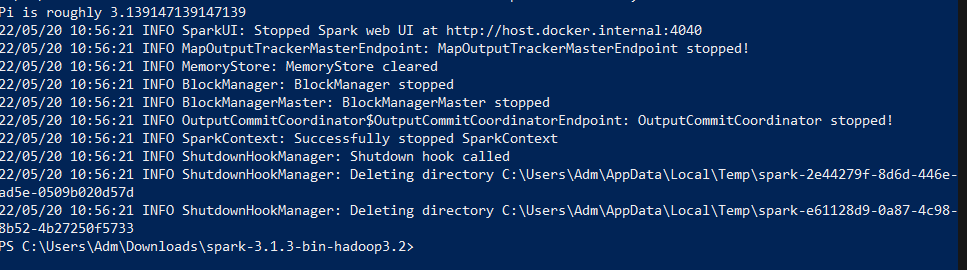
Here is the command we issued :
.bin/spark-submit –class org.apache.spark.examples.SparkPi –master local examples/jars/spark-examples_2.12-3.1.3.jar 10
In this example we have several arguments in the spark-submit command including :
– master where to specify the cluster on which we want to launch or run our application: in our case it is the local one because we are on our machine but we can do it on another cluster like standalone, yarn or mesos, for example.
– class : in our case it is the SparkPi class from org.apache.spark.examples
– And the path of the file we want to launch. In our case it is a java archive: examples/jars/spark-examples_2.12-2.2.0.jar
We can launch our applications with any supported language by Spark
Dataset : Dataset in Spark
Datasets in Spark are a data structure with which we can create our own objects and be sure not to end up with elements of another type. For example, an Info type dataset will only contain Info type objects. They are therefore parameterized with the type of data you want to store: Dataset[T] in scala or Dataset in java.
It’s a bit like Arraylists in Java and Sequences (Seq) in Scala. This data structure is only available in java and scala in Spark.
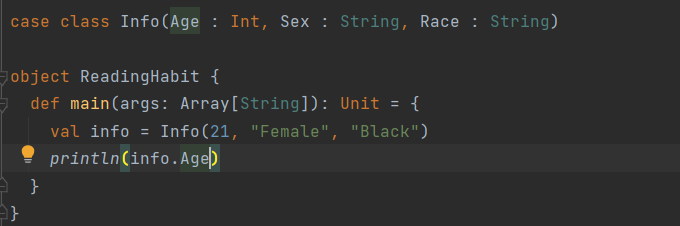
In this example, we create an Info class and show how to create an object of type Info and display one of its attributes.
Structured Streaming
It’s the Apache Spark API that lets you express a computation over streaming data the same way you express a batch computation over static data. The Spark SQL engine performs the calculation incrementally and continuously updates the result as streaming data arrives.
Machine learning
Spark also allows machine learning with a dedicated library called MLlib. It provides all the necessary tools for the different steps from data preparation, to prediction on a data scale. We also have the possibility of using loan models ranging from classification to deep learning.
Exemple : K-means
It is an unsupervised clustering algorithm in which the data is separated into a cluster in which the squared distance between the data points and the centroid is minimale.
We explain below the different steps (in general) of a K means algo
– Bring all the data in digital format: String Indexer or One hot encoder
– Separate data into training and testing sets: where clause with dates, validation splits or cross validation
– Assemble the data into a vector. All ML algorithms take vectors of numeric values as input: VectorAssembler
– set up the first 3 setps in a pipeline so that all future data that we need to transform can follow exactly the same process: Pipeline
– Adapt our pipeline to all training data: fit
– Transform our data from the pipeline adapted to the data: transform
– We could have included kmeans in the pipeline, but we will hide the dataset prepared for kmeans in order to test it quickly with different parameters: tranform.cache
– Instantiate our model: Kmean for untrained models, and KmeanModel for trained models
– Train the model: fit
– Calculate the cost based on some merits of success on our transformation: computeCost

SparkR
SparkR is the library adapted to do R with Spark. To use it, you just have to import the library into your programming environment and run your code. It’s about the same elements as with python, but just following the R syntax. It is also possible to import the other R libraries.
One of the particularities of Spark also lies in the multitude of tools and packages created by the community (around 300 packages available). https://spark-packages.org/.
We have seen in this article all the tools of Spark in a global way, we will see in the following in detail each of these elements.
L’une des particularités de Spark réside aussi dans la multitude d’outils et de packages créés par la communauté (environ 300 packages disponible). https://spark-packages.org/.
Nous avons vu dans cet article l’ensemble des outils de Spark de façon globale, nous verrons dans la suite en détail chacun de ces éléments.




