Spark pour les nuls – Partie 3 – Vue d’ensemble

Spark est un framework simple, rapide avec des librairies qui aident à une analyse précise d’un grand ensemble de données dans plusieurs langages.
Nous aurons dans cet article une vue d’ensemble de ces outils.
Nous décrivons brièvement à quoi sert chacun d’eux et comment l’utiliser.

Exécution d’une application en production
Spark nous permet de facilement créer des applications en production avec la commande : spark-submit.
Elle nous permet d’envoyer notre application à un cluster, de l’y lancer et de l’exécuter.
Voici un exemple pour illustrer cela avec une application scala disponible dans le dossier d’installation de Spark.
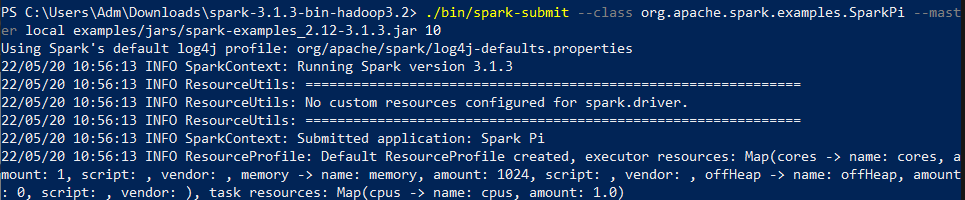
Voici la commande que nous avons lancé :
.bin/spark-submit –class org.apache.spark.examples.SparkPi –master local examples/jars/spark-examples_2.12-3.1.3.jar 10
Dans cet exemple nous avons plusieurs arguments dans la commande spark-submit dont :
– master où spécifier le cluster sur lequel nous voulons lancer ou exécuter notre application : dans notre cas il s’agit du local parce que nous sommes sur notre machine mais nous pouvons le faire sur un autre cluster comme standalone, yarn ou mesos, par exemple.
– class : dans notre cas il s’agit de la classe SparkPi de org.apache.spark.examples
– Et le chemin du fichier que nous voulons lancer. Dans notre cas il s’agit d’une archive java : examples/jars/spark-examples_2.12-2.2.0.jar
Nous pouvons lancer nos applications avec n’importe quel langage supporté par Spark.
Dataset : API structurée de type sécurisé
Les Dataset en Spark sont une structure de données avec lequel on peut créer nos propres objets et être sûr de ne pas se retrouver avec des éléments d’un autre type. Par exemple, un dataset de type Info ne contiendra que des objets de type Info. Elles sont donc paramétrées avec le type de la donnée que vous voulez stocker : Dataset[T] en scala ou Dataset en java.
C’est un peu comme les Arraylist en Java et les séquences (Seq) en Scala. Cette structure de données n’est disponible qu’en java et en scala dans Spark.
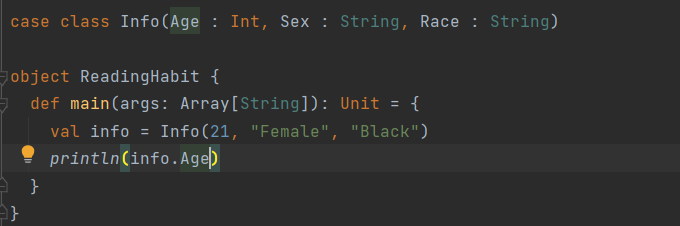
Dans cet exemple, on crée une classe Info et on montre comment créer un object de type Info et afficher l’un de ses attributs.
Diffusion structurée
C’est l’API Apache Spark qui vous permet d’exprimer un calcul sur des données de streaming de la même manière que vous exprimez un calcul par lots sur des données statiques. Le moteur Spark SQL effectue le calcul de manière incrémentielle et met à jour en continu le résultat à mesure que les données de streaming arrivent.
Machine learning et analyse avancée
Spark permet également de faire du machine learning avec une librairie dédiée appelée MLlib. Elle fournit tous les outils nécessaires pour les différentes étapes de la préparation des données, à la prédiction sur une échelle de données. On a également la possibilité d’utiliser des modèles prétaités allant de la classification au deep learning.
Exemple : K-means
C’est un algorithme de clustering non supervisé dans lequel les données sont séparées en un cluster dans lequel la distance au carré entre les points de données et le centroïde est minimale.
Nous expliquons ci-dessous les différentes étapes (de façon générale) d’un algo de K-means
– Ramener toutes les données au format numérique : String Indexer ou One hot encoder
– Séparer les données en training et testing sets : clause where avec les dates, validation splits ou cross validation
– Assembler les données dans un vecteur. Tous les algos de ML prennent en entrée des vecteurs de valeurs numériques : VectorAssembler
– mettre en place les 3 premiers setps dans un pipeline afin que toutes les données futures que nous devons transformer puissent suivre exactement le même processus : Pipeline
– Adapter notre pipeline à l’ensemble des données de training : fit
– Transformer nos données à partir de la pipeline adaptée aux données : transform
– On aurait pu inclure kmeans dans la pipeline, mais on va cacher le dataset préparé pour kmeans afin de le tester rapidement avec différents paramètres : tranform.cache
– Instancier notre modèle : Kmean pour les modèles non entrainés, et KmeanModel pour les modèles entrainés
– Entrainer le modèle : fit
– Calculer le coût en fonction de certains mérites de réussite sur notre transformation : computeCost

SparkR
SparkR est la librairie adaptée pour faire du R avec Spark. Pour l’utiliser, il faut juste importer la librairie dans votre environnement de programmation et exécuter votre code. C’est à peu près les mêmes éléments qu’avec python, mais suivant juste la syntaxe de R. Il est également possible d’importer les autres librairies de R.
L’une des particularités de Spark réside aussi dans la multitude d’outils et de packages créés par la communauté (environ 300 packages disponible). https://spark-packages.org/.
Nous avons vu dans cet article l’ensemble des outils de Spark de façon globale, nous verrons dans la suite en détail chacun de ces éléments.



