Spark pour les nuls – Partie 5 – Opérations de bases sur les API structurées

Dans cet article, nous allons voir quelques opérations sur les Dataframes. Avant de continuer la lecture, je vous recommande, si ce n’est pas encore fait, de lire le tout premier article de la série (que vous trouverez ici) : https://data-mindset.fr/spark-pour-les -nuls-partie-1/
Petit rappel : Les Dataframes sont des tables comme des collections de lignes et de colonnes, bien définies. Ils sont immuables et évalués paresseusement. Lorsque nous effectuons une action sur un Dataframe, nous demandons à Spark d’effectuer les transformations et de renvoyer le résultat.

Partitionnement
Une partition dans Spark n’est rien d’autre qu’une disposition de la distribution physique du Dataframe ou de l’ensemble de données dans le cluster.
Prenons un exemple :
//reading a csv file with schema on read
val df = spark.read.options(Map("inferSchema" -> "true", "delimiter" -> ",", "header" -> "true", "multiline" -> "true"))
.csv("C:/Users/boros/Documents/S10_Stage_Data/online-retail.csv")
// showing the number of partitions of this dataframe
println("The initial dataframe has " + df.rdd.partitions.size + " partition")
La sortie dans notre exemple est :
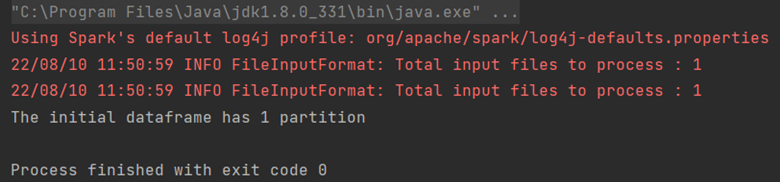
Nous avons ici créé un Dataframe simple en lisant un fichier csv, et nous affichons le nombre de partitions.
Schéma
Comme nous l’avons vu dans l’article précédent, le schéma d’un Dataframe est la liste des noms et des types des colonnes de ce dataframe.
Il peut être récupéré dynamiquement (« schema on read », qui signifie schéma lors de la lecture) si rien n’est codé, mais cela peut entraîner un problème de précision (par exemple, un type de colonne sera « Integer » au lieu de « Long » lors de la lecture des données).
Le schéma peut également être défini pour les sources de données non typées.
Type = StructType (List(StructField(name, spark type, nullable)))
Nous illustrons ici le principe du « schéma en lecture » avec un exemple où le schéma d’une dataframe est lu à partir d’un fichier CSV
//reading a csv file with schema on read
val df = spark.read.options(Map("inferSchema" -> "true", "delimiter" -> ",", "header" -> "true", "multiline" -> "true"))
.csv("path of your csv file")
println(df.schema)
Le paramètre inferSchema affecté à true devinera automatiquement les types de données pour chaque champ de votre fichier CSV.
Ici, la sortie sera :

Colonnes et expressions
Les colonnes de Spark sont équivalentes aux colonnes de Pandas en Python. On peut les manipuler avec des sélections, des suppressions, des ajouts ou des mises à jour en tant qu’expressions.
Une expression est un ensemble de transformations sur une ou plusieurs valeurs lues dans une dataframe.
Pour faire fonctionner l’exemple ci-dessous, on devra importer préalablement :org.apache.spark.sql.functions.col/column
Voici des exemples d’expressions :
expr (« expression »)
expr (« nomdelacolonne ») <=> col(« nomdelacolonne »)
Considérons un exemple :
expr ("nomdelacolonne” - 5) <=> col("nomdelacolonne") - 5 <=>
expr("nomdelacolonne") - 5
Ici, les 3 expressions sont équivalentes et ont le même schéma logique.
Une implémentation de cet exemple est :
df.select(expr("Quantity + 5 as new_quantity")).show(3)
df.select(col("Quantity") + 5).show(3)
df.select(expr("Quantity") + 5 ).show(3)Étant donné que le schéma logique est similaire pour ces 3 expressions, les résultats sont également similaires :
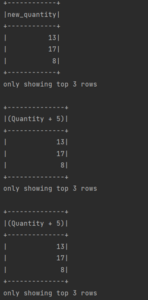
Pour afficher les colonnes d’un Dataframe, utilisez simplement la méthode columns

Par exemple:
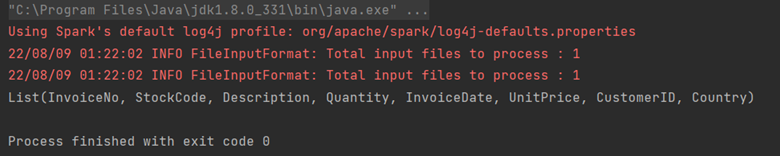
//reading a csv file with schema on read
val df = spark.read.options(Map("inferSchema" -> "true", "delimiter" -> ",", "header" -> "true", "multiline" -> "true"))
.csv("C:/Users/boros/Documents/S10_Stage_Data/online-retail.csv")
println(df.columns.toList)
La sortie sera :
Lignes et enregistrements
Chaque ligne d’un Dataframe est un enregistrement unique et, à l’intérieur de ce Dataframe en Spark, il s’agit d’un objet de type Row.
Les objets Row dans Spark sont des représentations internes d’un tableau en octets.
Il existe de nombreuses façons de sélectionner des lignes d’un Dataframe en fonction de conditions, en utilisant :
- La méthode filter:
- //reading a csv file with schema on read
val df = spark.read.options(Map("inferSchema" -> "true", "delimiter" -> ",", "header" -> "true", "multiline" -> "true"))
.csv("C:/Users/Documents/online-retail.csv")
//filter
df.filter(col("country") === "USA").show()
La sortie correspondante sera :
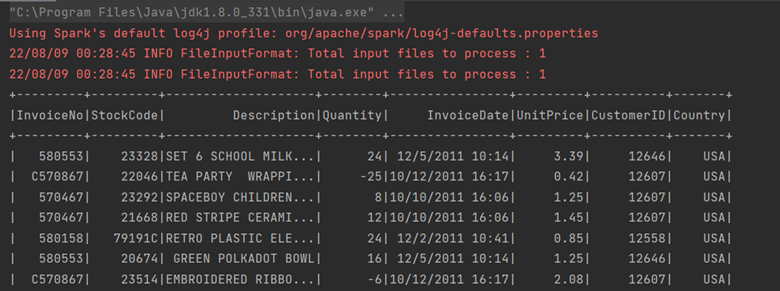
- La méthode where :
//reading a csv file with schema on read
val df = spark.read.options(Map("inferSchema" -> "true", "delimiter" -> ",", "header" -> "true", "multiline" -> "true"))
.csv("C:/Users/Documents/online-retail.csv")
//where
df.where(col("country") === "USA").show()La sortie correspondante sera :
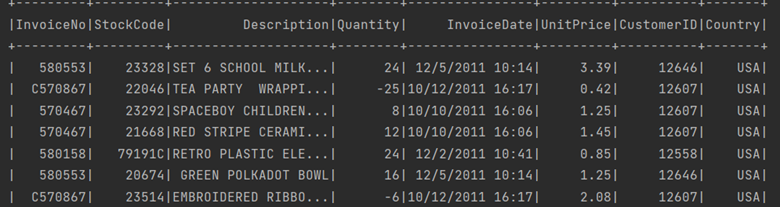
Pour afficher la première ligne d’un Dataframe, utilisez juste la méthode first :
//reading a csv file with schema on read
val df = spark.read.options(Map("inferSchema" -> "true", "delimiter" -> ",", "header" -> "true", "multiline" -> "true"))
.csv("C:/Users/Documents/online-retail.csv")
println(df.first())
La sortie correspondante :

Pour créer une ligne dans votre code, instanciez un objet de type Row comme suit :
Row (value1, value2, … , valuen)
Notez que les paramètres doivent être dans le même ordre que le schéma du Dataframe.
Dans l’exemple ci-dessous, nous créons un Dataframe contenant des villes américaines à partir du code :
val schema = StructType(Array(StructField("Ville", StringType, true), StructField (name="Pays", StringType, true)))
val rows = Seq(Row ("Los Angeles", "United States"), Row ("New York", "United States"), Row ("London", "United Kingdom"))
val parallelizeRows = spark.sparkContext.parallelize(rows)
val df = spark.createDataFrame(parallelizeRows, schema)
df.show()
En sortie nous avons:
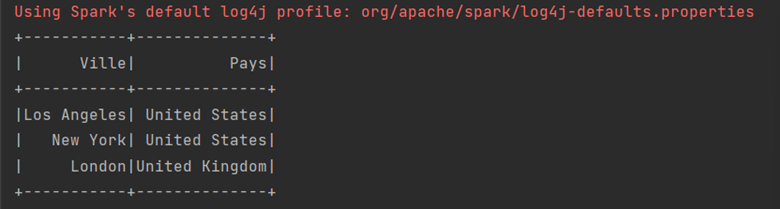
Select et Select Expr
Pour sélectionner une colonne, nous pouvons :
– utiliser directement le nom de la colonne
– utiliser le nom de la colonne à l’intérieur d’une expression : cette méthode conduit à des transformations à l’intérieur de la méthode expr.
Ci-dessous un exemple avec les deux méthodes de sélections :
reading a csv file with schema on read
val df = spark.read.options(Map("inferSchema" -> "true", "delimiter" -> ",", "header" -> "true", "multiline" -> "true"))
.csv("C:/Users/Documents/online-retail.csv")
df.select("Description").show(5)
df.select(expr("Description as desc")).show(5)
La sortie est:
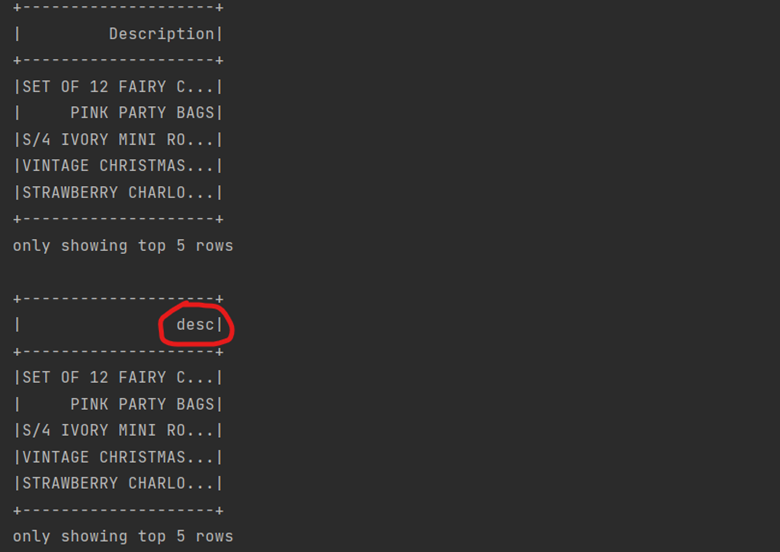
Limit
La méthode limit est utile lorsque nous devons extraire une partie du Dataframe.
En règle générale, nous ne voulons que les 5, 10 ou 100 meilleurs résultats à partir des données.
À titre d’exemple, nous utiliserons le Dataframe précédent et appliquerons une limite de 10
//reading a csv file with schema on read
val df = spark.read.options(Map("inferSchema" -> "true", "delimiter" -> ",", "header" -> "true", "multiline" -> "true"))
.csv("C:/Users/Documents/online-retail.csv")
df.select("Description").show(5)
df.select(expr("Description as desc")).show(5)
println(df.limit(10).show())
La sortie correspondante est:
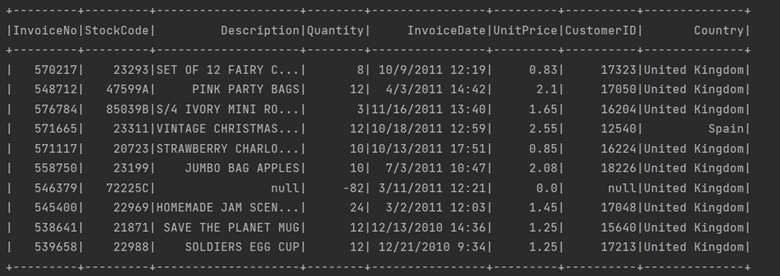
Repartition et coalesce
La méthode de répartition peut être utilisée pour augmenter le nombre de partitions dans un Dataframe.
Spark répartit les données de manière équilibré au sein de sone cluster, et un remaniement conduit à un lourd échange de données au travers le cluster tout entier. Ce phénomène est appelé shuffle en anglais.
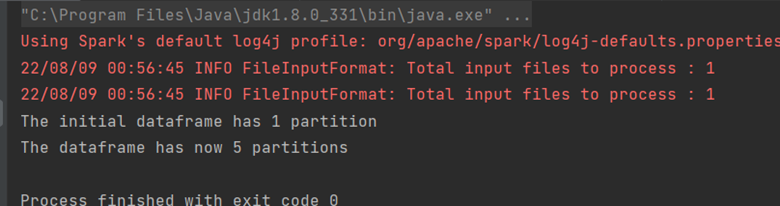
Voyons un exemple avec le premier Dataframe que nous avons créé qui avait initialement une seule partition.
//reading a csv file with schema on read
val df = spark.read.options(Map("inferSchema" -> "true", "delimiter" -> ",", "header" -> "true", "multiline" -> "true"))
.csv("C:/Users/Documents/online-retail.csv")
// showing the number of partitions of this dataframe
println("The initial dataframe has " + df.rdd.partitions.size + " partition")
//increasing the number of partitions
val df1 = df.repartition(5)
println("The dataframe has now " + df1.rdd.partitions.size + " partitions")
La sortie correspondante est:
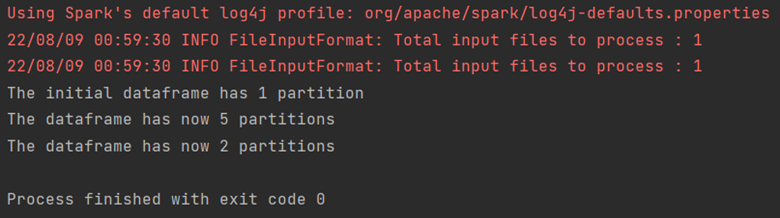
D’autre part, la méthode de coalescence réduit le nombre de partitions dans le Dataframe.
Elle évite le shuffle, mais les données ne seront pas réparties de manière équilibrée dans le cluster Spark, ce qui peut entraîner un trop fort déséquilibre au niveau de la taille des partitions. Ce phénomène est appelé data skew en anglais. Pour cette raison, il est important d’analyser les données et le besoin avant d’utiliser la répartition ou la coalescence.
val df2 = df1.coalesce(2)
println("The dataframe has now " + df2.rdd.partitions.size + " partitions")
La sortie correspondante est:
Résumons les avantages et inconvénients de répartition et coalesce:
| « Shuffle » | Possible « Data Skew » | |
| Répartition | Oui | Non |
| Coalesce | Non | Oui |
Collecte de lignes jusqu’au Driver Spark
Nous pouvons récupérer des données à partir d’un Dataframe, avec la méthode collect.
Attention : de cette manière, nous collectons l’intégralité du Dataframe depuis les exécuteurs Spark jusqu’au Driver Spark qui peut planter si le Dataframe est trop volumineux.
Généralement nous n’aurons besoin de collecter qu’un échantillon de lignes avec la méthode take.
//reading a csv file with schema on read
val df = spark.read.options(Map("inferSchema" -> "true", "delimiter" -> ",", "header" -> "true", "multiline" -> "true"))
.csv("C:/Users/Documents/online-retail.csv")
println(df.collect().toList.take(2))
La sortie correspondante est:

Enfin, si vous souhaitez collecter les partitions une par une sur le Driver, utilisez la méthode toLocalIterator.
Cette méthode peut elle aussi planter le Driver Spark si les partitions sont très volumineuses. De plus, cela peut mettre beaucoup de temps, car Spark calcule les partitions une par une… et pas en parallèle!
Vous avez désormais plusieurs astuces pour commencer à travailler sur les Dataframes avec Spark. Bien sûr, nous n’avons pas couvert l’ensemble des méthodes existantes, mais cet aperçu est suffisant pour se lancer. Dans le prochain article, nous verrons comment travailler avec les différents types de données d’Apache Spark.