Spark pour les nuls – Partie 6 – Boîte à outils par type de données

Nous allons voir dans ce chapitre les différents types gérés par Spark et leurs principales fonctionnalités.
Cette liste couvre la majorité des besoins mais n’est pas exhaustive.
Vous retrouverez tout ce dont vous avez besoin au niveau de la classe org.apache.spark.sql.functions
Pour cet article nous avons utilisé la plateforme Databricks ainsi que le langage Python pour la rédaction du code.
Conversion en colonne typée Spark
La méthode lit permet de convertir un objet en une colonne contenant cet objet en type Spark.
C’est très pratique pour convertir les constantes du langage utilisé en type Spark, par exemple :
allumé(3), allumé(« trois »)

from pyspark.sql.functions import col,lit
df1 = df.select(col("id"),col("Nom"),col("Profession"),lit("2").alias("lit_valeur"))
df1.show(truncate=False)

Travailler avec des booléens
La méthode where permet de filtrer les données selon une condition donnée en paramètre, qui peut être :
• Une expression SQL, par exemple : where(« c=1 »)
df1.where("id==2").show()
• Une condition sous forme de colonne, par exemple : where col(c)==1
df1.where(col("Profession")=="professeur").show()
Il est alors possible de chaîner les filtres où , ce qui est équivalent à utiliser l’opérateur et .
df1.where(df1.Nom == 'Laurent').where (df1.Profession == 'Docteur').show()
df1.where(df1.Nom == 'Laurent' and df1.Profession == 'Docteur').show()
Attention, un test de type « == » entre deux valeurs nulles renvoie false ; si l’on veut comparer des valeurs en spécifiant que les valeurs nulles sont égales, on doit utiliser l’opérateur eqNullSafe .
df.select(
df['Profession'],
(df['Profession'] == 'ingenieur').alias("EgalIngenieur"),
(df['Profession'] == None).alias("EgalNone"),
df['Profession'].eqNullSafe('ingenieur').alias("EqNullSafeIngenieur"),
df['Profession'].eqNullSafe(None).alias("EqNullSafeNone")
).show()

Les nombres
Il est possible d’utiliser les nombres dans une expression, ou bien leur valeur dans le code.
Pour arrondir les nombres on peut soit les convertir en entier avec la commande suivante :
df1.select(col("c").cast("int").as("c")).show() soit utiliser les méthodes round (arrondi supérieur) ou bround (arrondi inférieur)
La méthode corr permet de calculer la corrélation entre deux colonnes :Dataframe.corr(« col1″, »col2 » ).
Les chaînes de caractère
Spark offre un ensemble d’outils qui nous permet de faire la plupart des opérations de base sur les chaînes de caractères :
• La méthode initcap permet de capitaliser le premier caractère de chaque mot d’une chaîne de caractère
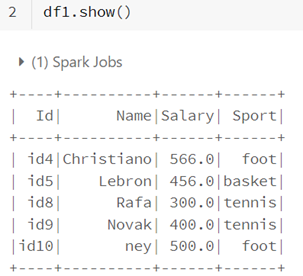
from pyspark.sql.functions import initcap
df1.select(initcap("Sport")).show()
• Pour mettre tous les caractères d’une chaine en majuscule, il suffit d’utiliser la méthode upper
from pyspark.sql.functions import upper, lower, col
df1.select(upper("Name")).show()
La méthode inférieure permet de mettre les caractères d’une chaine en minuscule
df1.select(lower("Name")).show()
• Les fonctions lpad/rpad sont utilisées pour formater les données si nécessaires
from pyspark.sql.functions import lpad, rpad
df1.select("Sport", \
"salary", \
lpad(trim(col("salary")), 4, "0").alias("formmated_data") \
).show()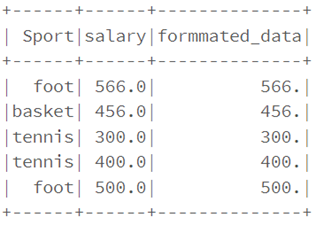
• les fonctions : trim, ltrim et rtrim sont utilisées pour supprimer les espaces blancs de début et fin de données
from pyspark.sql.functions import lpad, rpad
df1.select(ltrim("salary")).show() 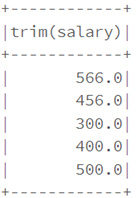
• Avec la fonction regexp_replace nous pouvons remplacer n’importe quelle chaîne correspondant à un modèle d’expression régulière par une autre chaîne de caractères :
from pyspark.sql.functions import regexp_replace
reg_exp = "foot"
df1.select(regexp_replace \
(col("Sport"), \
reg_exp,"football") \
.alias("sports"), "Sport") \
.show()
• La fonction translate remplace un ensemble ordonné de caractères représenté par une chaîne de caractères par d’autres caractères modélisés par un autre ensemble ordonné de caractères
from pyspark.sql.functions import translate
df1.select(translate \(col("Sport"), \"ito", "ITO") \.alias("Nouveau") \).show()

• Instr renvoyé 1 si une chaîne en contient une autre, 0 sinon
from pyspark.sql.functions import instr
df1.select("Sport", \instr(col("Sport"), \"foot")).show()
Les dates et timestamps
Il existe dans l’API DataFrame de Spark des fonctions sur les dates et horodatages, qui permettent d’effectuer diverses opérations sur la date et l’heure.
La méthode current_date permet d’afficher la date courante

dataf.select(current_date().alias("current_date")).show(1)
La méthode date_add permet d’ajouter ou de retirer un ou plusieurs jours à une date
dataf.select(col("date"),
date_add(col("date"),4).alias("date_add"),
date_sub(col("date"),4).alias("date_sub")
).show()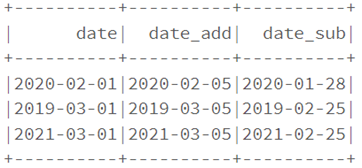
La fonction date_diff renvoie le nombre de jours entre deux dates
dataf.select(col("date"),
datediff(current_date(),col("date")).alias("datediff")
).show()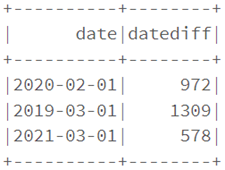
Traiter les données null
La valeur nulle peut être utilisée pour représenter une donnée manquante ou vide. Elle permet d’effectuer facilement des opérations de nettoyage, comme :
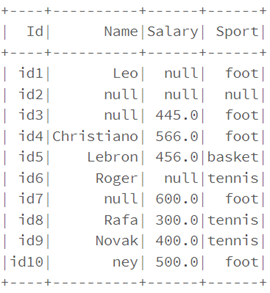
• Supprimer les lignes contenant des valeurs null
df.na.drop("any").show()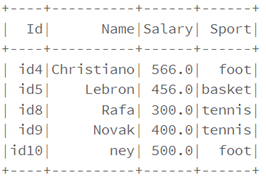
• Remplacer des valeurs null par d’autres valeurs entières ou de type chaîne de caractères
df.na.fill("Incomplet").show()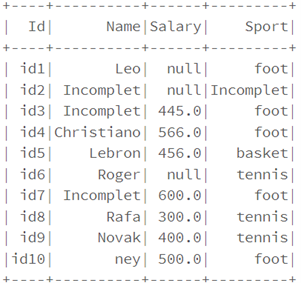
df.na.fill(0).show()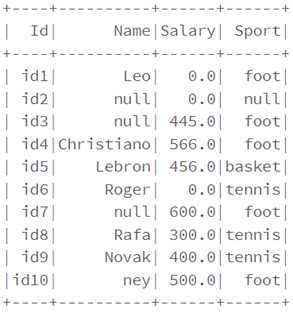
Pour la valeur de type double, la syntaxe est : df.na.fill(double)
Les types complexes
Les types complexes contiennent plusieurs valeurs au sein d’une même colonne. Il existe plusieurs types de données complexes tels que les structures (struct), les tableaux (arrays), les tables de correspondance clé-valeur (maps) ou encore le format standard JSON.
Structs
Le type Struct définit un ensemble de valeurs dont les types peuvent être différents (primitifs ou complexes)
Pour cela, il suffit de définir un schéma.
Par exemple, pour la structure ci-dessous :
from pyspark.sql.types import StructType,StructField, StringType,IntegerType
struct_donnee= [
(("jean","Brice"),"M",23),
(("Olivier","Benoit"),"M",40),
(("Agnès","Piccardi"),"F",26)
]Le schéma correspondant est le suivant :
struct_schema=StructType([
StructField('Infos', StructType([
StructField('Prenom',StringType(), True),
StructField('Nom',StringType(), True)
])),
StructField('genre', StringType(), True),
StructField('Age', IntegerType(),True)
])
df_struct.select("Infos.*","genre","age").printSchema()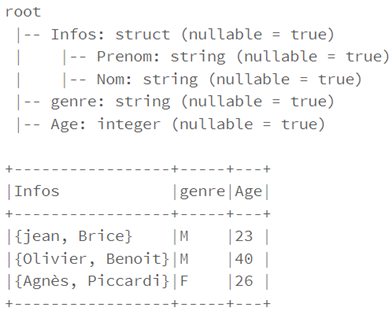
Les tableaux (Arrays)
Un tableau est une collection ordonnée d’éléments de type complexe ou primitif.
Attention : tous les éléments d’un tableau doivent être du même type de donnée, par exemple :
from pyspark.sql.functions import col,array_contains
from pyspark.sql import Row
df_array= spark.createDataFrame([Row(chiffre=[1,2,3],Nom="Brice"),Row(chiffre=[11,22,33],Nom="Olivier"),Row(chiffre=[111,222,333],Nom="Agnès")])
df_array.show(truncate=False)
La méthode split permet de transformer une chaîne de caractères en un tableau où chaque élément est un caractère de la chaîne, par exemple :
from pyspark.sql.functions import split
df_array.select(split(col("Nom"),"")).show()
• Pour obtenir l’élément d’un tableau correspondant à une donnée de position, on peut utiliser select_expr avec sa position entre crochets
df_array.selectExpr("chiffre[0]").show()La fonction size renvoie la taille d’un tableau
from pyspark.sql.functions import size
df_array.select(size(col("chiffre"))).show()• Vérifier si un tableau contient une valeur passée en paramètre :
df_find=df_array.filter(array_contains(df_array.chiffre,33))
df_find.show()• Pour « exploser » un tableau sur plusieurs lignes , ou en d’autres termes obtenir une ligne pour chaque élément du tableau, on utilisera la méthode exploser

df_explode=df.select(df.Nom,explode(df.langage).alias("explode"))
df_explode.printSchema()
df_explode.show(truncate=False)
Les Maps
A l’inverse des tableaux, les cartes sont des collections d’éléments non ordonnés par paires de clés et de valeurs.
Les valeurs peuvent être de type primitif ou complexe. En revanche, les clés doivent être de type primitif, par exemple :
Exemple :
data= [({'a':1,'b':2},),({'c':3},), ({'a':4,'c':5},)]
df_map=spark.createDataFrame(data, ["map"])
df_map.show()
df_map.printSchema()

JSON
Dans Spark nous avons un accès à des fonctions dédiées au format JSON qui permettent d’effectuer différentes opérations.
Par exemple :
from pyspark.sql.functions import from_json,col
df=spark.read.json("/FileStore/tables/devices.json")

• La commande suivante permet d’afficher des colonnes spécifiques à partir d’un format JSON
df.select("device_id","zipcode").show(3)

• Pour convertir des chaines de caractères au format JSON en type Struct ou Map, on utilise la méthode from_json
from pyspark.sql.types import MapType,StringType
df.withColumn ("device_name",from_json(col("device_name"),MapType(StringType,StringType)))
• La méthode to_json() quant à elle, est utilisée pour convertir des types Map ou Struct en format json
from pyspark.sql.functions import to_json
df.withColumn("device_name",to_json(col("device_name")))
Conclusion
Nous avons vu dans cet article que Spark propose une très grande variété d’outils que nous venons de lister de manière simple et non exhaustive. Nous verrons par la suite que Spark offre bien d’autres possibilités.




