Spark for Dummies - Part 6 - Toolkit by Data Type

In this chapter we will see the different types managed by Spark and their main features.
This list covers most needs but is not exhaustive.
You will find everything you need in the org.apache.spark.sql.functions class
For this article we used the Databricks platform and the Python language to write the code.
Conversion to Spark-type column
The method lit allows to convert an object into a column containing this object in Spark type.
This is very useful to convert constants from the language used to Spark type, for example:
lit(3), lit(« three »)

from pyspark.sql.functions import col,lit
df1 = df.select(col("id"),col("Nom"),col("Profession"),lit("2").alias("lit_valeur"))
df1.show(truncate=False)

Working with Booleans
The where method allows to filter the data according to a condition given in parameter, which can be :
• An SQL expression, for example: where(« c=1 »)
df1.where("id==2").show()
• A condition in the form of a column, for example: where col(c)==1
df1.where(col("Profession")=="professeur").show()
It is then possible to chain the where filters where , which is equivalent to using the and operator and .
df1.where(df1.Nom == 'Laurent').where (df1.Profession == 'Docteur').show()
df1.where(df1.Nom == 'Laurent' and df1.Profession == 'Docteur').show()
Attention, a test of type « == » between two null values returns false; if you want to compare values by specifying that null values are equal, you must use the eqNullSafe operator eqNullSafe .
df.select(
df['Profession'],
(df['Profession'] == 'ingenieur').alias("EgalIngenieur"),
(df['Profession'] == None).alias("EgalNone"),
df['Profession'].eqNullSafe('ingenieur').alias("EqNullSafeIngenieur"),
df['Profession'].eqNullSafe(None).alias("EqNullSafeNone")
).show()

The numbers
It is possible to use numbers in an expression, or their value in the code.
To round numbers you can either convert them to integers with the following command:
df1.select(col("c").cast("int").as("c")).show() or use the round up or round down methods
The method corr is used to calculate the correlation between two columns: Dataframe.corr(“col1″,”col2” ).
Character strings
Spark offers a set of tools that allows us to do most of the basic string operations:
• Theinitcap method allows to capitalize the first character of each word of a string
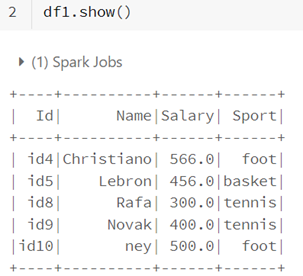
from pyspark.sql.functions import initcap
df1.select(initcap("Sport")).show()
• To capitalize all the characters of a string, just use the upper method The lower method allows to put the characters of a string in lower case • he lpad/rpad functions are used to format the data if necessary • the functions :trim, ltrim and rtrim functions are used to remove white spaces at the beginning and end of data • With the regexp_replace function we can replace any string corresponding to a regular expression pattern with another string: • The translate function replaces an ordered set of characters represented by a string with other characters modeled by another ordered set of characters • Instr returns 1 if a string contains another string, 0 otherwise There are date and timestamp functions in the Spark DataFrame API, which allow you to perform various date and time operations. The current_date method displays the current date The date_add method allows you to add or remove one or more days to a date The date_diff function returns the number of days between two dates The null value can be used to represent missing or empty data. It allows to easily perform cleaning operations, such as: • Delete rows containing null valuesnull • Replace null values by other integer or string values For double values, the syntax is : df.na.fill(double) Complex types contain multiple values within a single column. There are several complex data types such as structures (struct), arrays (arrays), key-value mapping tables (maps) or the standard JSON format. The Struct type defines a set of values whose types can be different (primitive or complex) The corresponding diagram is as follows: An array is an ordered collection of elements of complex or primitive type. The split method allows you to transform a string into an array where each element is a character of the string, for example: • To get the element of an array corresponding to a given position, we can use select_expr with its position in square brackets The size function returns the size of an array • Check if an array contains a value passed in parameter : To “explode” an array on several rows, or in other words to obtain a row for each element of the array, we will use the • explode method Unlike arrays, maps are collections of elements not ordered by pairs of keys and values. In Spark we have access to functions dedicated to the JSON format that allow us to perform different operations. • The following command allows to display specific columns from a JSON format • To convert strings in JSON format into Struct or Map type, we use the from_json method • The to_json() method is used to convert Map or Struct types into json format We have seen in this article that Spark offers a very wide variety of tools that we have just listed in a simple and non-exhaustive way. We will see later that Spark offers many other possibilities.from pyspark.sql.functions import upper, lower, col
df1.select(upper("Name")).show()
df1.select(lower("Name")).show()
from pyspark.sql.functions import lpad, rpad
df1.select("Sport", \
"salary", \
lpad(trim(col("salary")), 4, "0").alias("formmated_data") \
).show()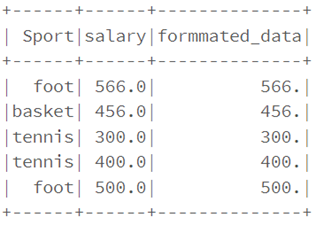
from pyspark.sql.functions import lpad, rpad
df1.select(ltrim("salary")).show() 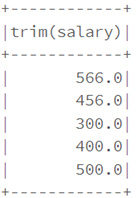
from pyspark.sql.functions import regexp_replace
reg_exp = "foot"
df1.select(regexp_replace \
(col("Sport"), \
reg_exp,"football") \
.alias("sports"), "Sport") \
.show()
from pyspark.sql.functions import translate
df1.select(translate \(col("Sport"), \"ito", "ITO") \.alias("Nouveau") \).show()

from pyspark.sql.functions import instr
df1.select("Sport", \instr(col("Sport"), \"foot")).show()
Dates and timestamps

dataf.select(current_date().alias("current_date")).show(1)
dataf.select(col("date"),
date_add(col("date"),4).alias("date_add"),
date_sub(col("date"),4).alias("date_sub")
).show()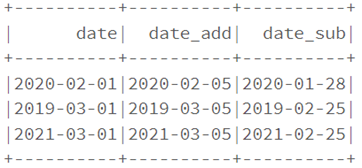
dataf.select(col("date"),
datediff(current_date(),col("date")).alias("datediff")
).show()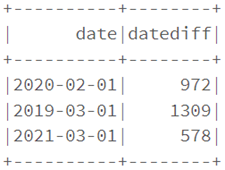
Process null data
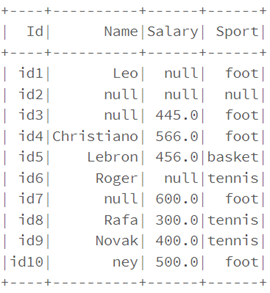
df.na.drop("any").show()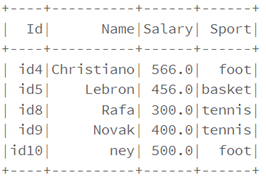
df.na.fill("Incomplet").show()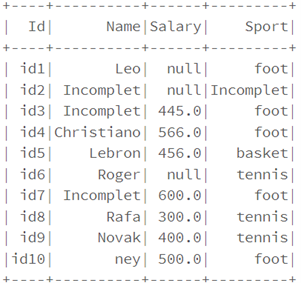
df.na.fill(0).show()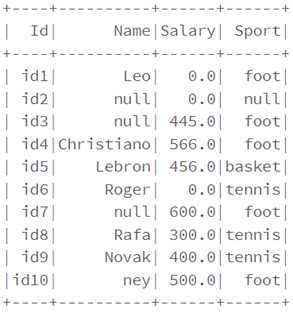
Complex types
Structs
To do this, all you have to do is define a scheme.
For example, for the structure below:from pyspark.sql.types import StructType,StructField, StringType,IntegerType
struct_donnee= [
(("jean","Brice"),"M",23),
(("Olivier","Benoit"),"M",40),
(("Agnès","Piccardi"),"F",26)
]struct_schema=StructType([
StructField('Infos', StructType([
StructField('Prenom',StringType(), True),
StructField('Nom',StringType(), True)
])),
StructField('genre', StringType(), True),
StructField('Age', IntegerType(),True)
])
df_struct.select("Infos.*","genre","age").printSchema()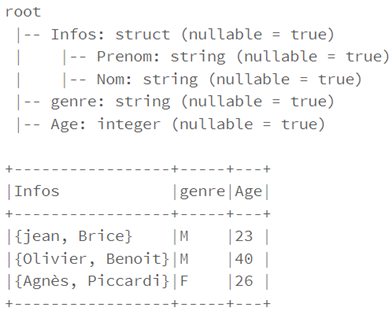
Arrays
Warning: all elements of an array must be of the same data type, for example:from pyspark.sql.functions import col,array_contains
from pyspark.sql import Row
df_array= spark.createDataFrame([Row(chiffre=[1,2,3],Nom="Brice"),Row(chiffre=[11,22,33],Nom="Olivier"),Row(chiffre=[111,222,333],Nom="Agnès")])
df_array.show(truncate=False)
from pyspark.sql.functions import split
df_array.select(split(col("Nom"),"")).show()
df_array.selectExpr("chiffre[0]").show()from pyspark.sql.functions import size
df_array.select(size(col("chiffre"))).show()df_find=df_array.filter(array_contains(df_array.chiffre,33))
df_find.show()
df_explode=df.select(df.Nom,explode(df.langage).alias("explode"))
df_explode.printSchema()
df_explode.show(truncate=False)
The Maps
The values can be of primitive or complex type.On the other hand, the keys must be of primitive type, for example:
Example :data= [({'a':1,'b':2},),({'c':3},), ({'a':4,'c':5},)]
df_map=spark.createDataFrame(data, ["map"])
df_map.show()
df_map.printSchema()

JSON
For example :from pyspark.sql.functions import from_json,col
df=spark.read.json("/FileStore/tables/devices.json")

df.select("device_id","zipcode").show(3)

from pyspark.sql.types import MapType,StringType
df.withColumn ("device_name",from_json(col("device_name"),MapType(StringType,StringType)))
from pyspark.sql.functions import to_json
df.withColumn("device_name",to_json(col("device_name")))
Conclusion



