Spark for dummies- Part 1 - Overview

Getting started with Apache Spark
Welcome on this serie of articles on Apache Spark,
one of the most in demand big data processing framework. We will see in this article couple of interesting things about Spark from its philosophy to the installation on your machine.

Apache Spark is explained as a unified computing engine and a set of libraries for parallel data processing on computer clusters, in Spark, the definitive guide book by Bill Chambers and Matei Zaharia.
Apache spark philosophy
Let’s dig into the concepts of unified computing engine and librairies. One of the important goal of spark is to offer a unified engine for parallel data processing by doing different applications like data load, sql queries, machine learning and streaming, focus on computing data, wherever the data is.
It also provides many librairies which is the final part of its components : API for common data analysis tasks. Spark SQL for structured data processing, ML Lib for machine learning, Stream processing and GraphX for graph processing. All those are on the Apache Spark Core.
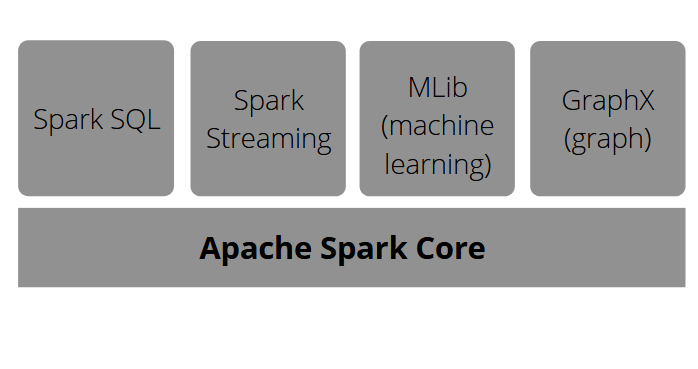
The context of Apache Spark creation
Before 2005, individual computers were made more and more fast by increasing the speed of their processors. It became difficult to fix hard limits in heat dissipation. Then hardware developers developed the process of adding more parallel CPU cores and that led to new models like apache spark.
The history of Apache Spark
► In 2009 : Everything started by the UC Berkeley research project. At this time, there was only Hadoop MapReduce, which, for multiple iterations, needed to load the data from scratch many times as needed, and write separate new jobs for machine learning algorithms. To resolve this problem, the team found the idea to create functional API programming to deal with multisteps applications with data in-memory.
The first version was for batch applications, interactive use for data scientists with scala and sql queries.
After these, these libraries were also designed : ML Lib, Streaming, GraphX on the same engine.
► In 2013 : The project became bigger with 100 contributors in 30 organizations : Databricks was launched.
► In 2014 : Version 1.0 Spark SQL for structured date
► In 2016 : Version 2.0 Structured Streaming
Actually, Spark is developing quickly and gain in popularity. Many companies started to use it (Uber, Netflix, NASA, CERN, …) for different use.
How to run Spark?
Let us see then how to run Spark on your computer. We can use Spark with Python, Java, Scala, R or SQL. Spark itself is written in scala and run on JVM. For any use of the python API, one needs a python interpreter of 2.7. For R, we need a version of R on the machine.
The official download link of the project : http://spark.apache.org/downloads.html
Spark for hadoop cluster, building from source
Interactive consoles (or shell)
For python pyspark : launch .bin/pyspark and type the command spark
For spark shell(scala) : launch .bin/spark-shell and type the command spark
For spark sql (sql) : launch .bin/spark-sql and type the command spark
On the cloud : use the databricks community edition (free) created by the berkeley team (scala, python, sql or R).
We will go through the entire installation of spark locally and with IntelliJ as IDE.

Spark installation locally
1. Download and Install Java JDK 8 or later
The more compatible java jdk for the latest version of spark are the java 8 or java 11.
The link to download it : https://www.oracle.com/java/technologies/downloads/#java8-windows
You will be asked to create an oracle account if you don’t have one. Create the account and run the file you downloaded.
After installing it, you could check if everything is ok by checking the version of java you have.
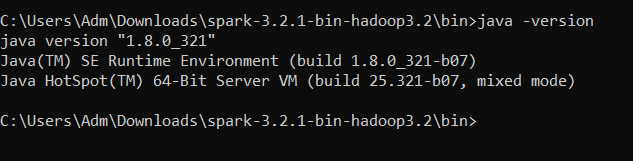
2. Download and install Apache Spark
The project official download link: http://spark.apache.org/downloads.html . Click on it to download the spark version you want. Here we choose the 3.2.1 version.
You should have this on the download page:
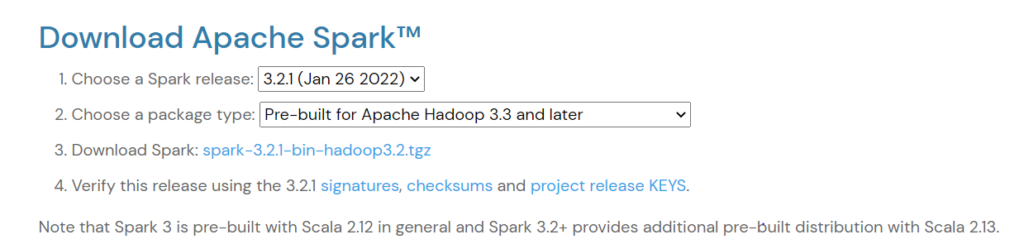
Click on download spark. The file would downloaded on your PC.
Then type the following commands to access the zip file.
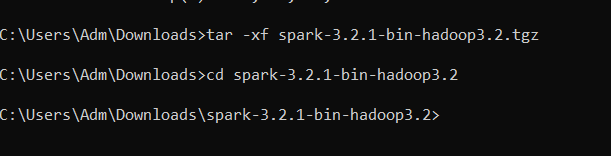
3. Download winutils.exe and hadoop.dll
Here is the link to download the winutils.exe file and the hadoop.dll file : https://github.com/cdarlint/winutils/tree/master/hadoop-3.2.1
Create a hadoop_home folder to the C:/ folder of your system. Inside of this folder, create another one named bin and put the files you downloaded.
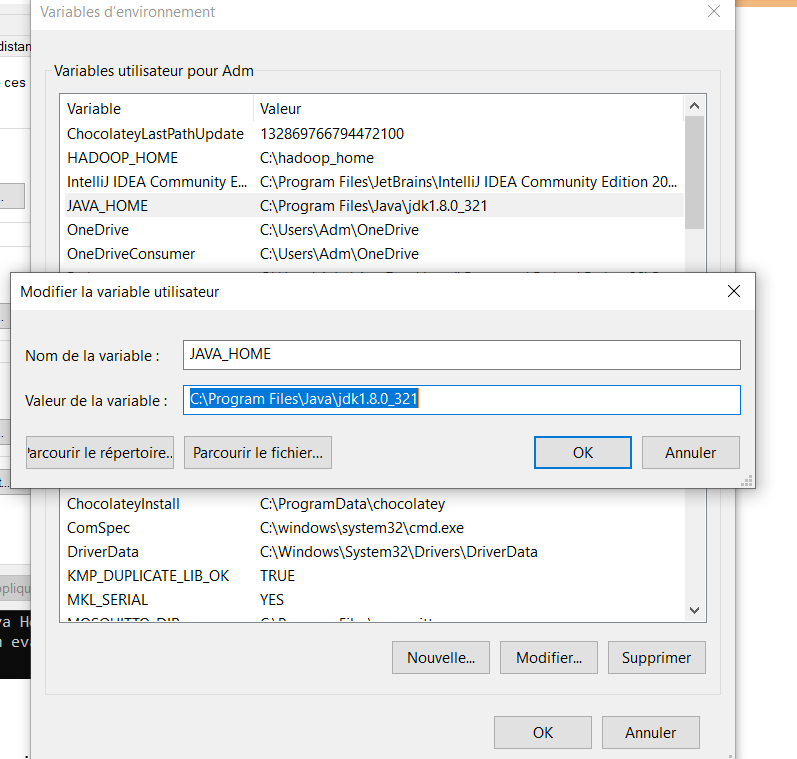
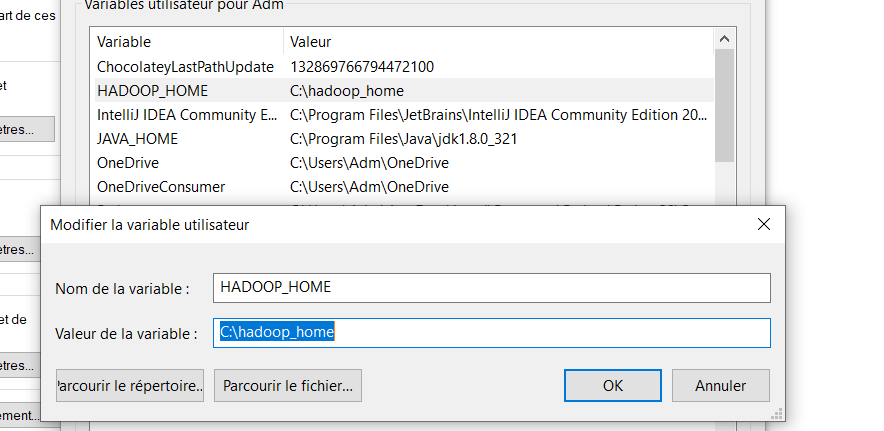
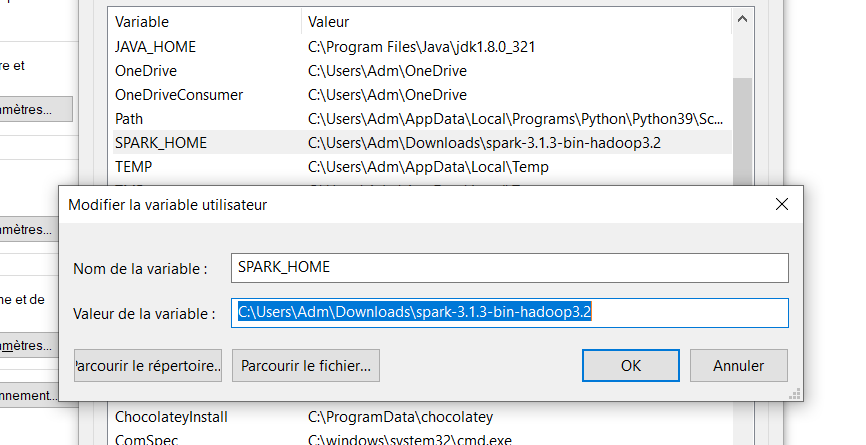
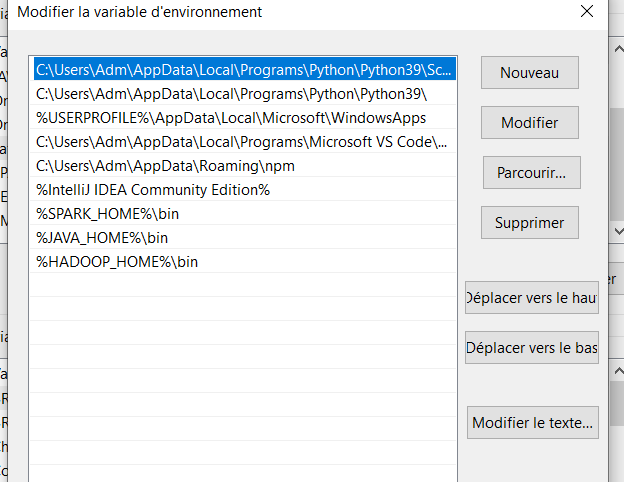
4. Define environment variables
Create the following variables in your environement variables and set the bin values to the path of java, spark and hadoop installed.
.
JAVA_HOME is the path to the jdk you installed;
SPARK_HOME is the path to the spark folder you downloaded;
HADOOP_HOME is the path to the hadoop_home you created.
You should have something like this at the end :
5. Launch the spark shell
Open the command prompt to the bin folder of your spark home and launch : spark-shell
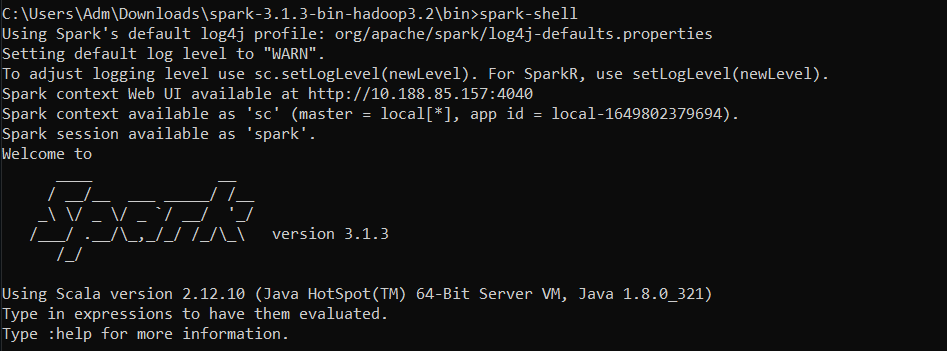
Félicitations ! Spark is successfully downloaded.

You can type : spark in the command prompt to see if there is a spark session created.

Spark installation with IntelliJ
You can also download an IDE with integrated scala plugin and spark librairies with SBT (SBT is a build tool for the JVM, like Maven or Gradle.
SBT est un outil de construction pour la JVM, comme Maven ou Gradle. From a project, it allows, among other things, to manage its dependencies, to compile, to run tests and to publish artifacts on repositories.)
In this articles, we will work with IntelliJ as IDE with scala plugin installed and spark 3.2.1 version.
Here is the link to download the community version of IntelliJ for JVM development: https://www.jetbrains.com/fr-fr/idea/download/#section=windows
To start working with Scala in IntelliJ IDEA you need to download and enable the Scala plugin.If you run IntelliJ IDEA for the first time, you can install the Scala plugin when IntelliJ IDEA suggests downloading featured plugins. Otherwise, you can use the Settings -> Plugins page for the installation.
Now that you have Spark installed on your computer, let’s see, in the next article, the architecture of Spark and its different part.



