Spark - Part 4 - Structured API Overview

How data are structured in Apache Spark ? What data types are supported in Spark ? How does Spark execute the code that is written in the cluster ? We answer these questions in this article.
Before jumping onto this, you might want to understand some basics concepts of Spark covered here : https://data-mindset.fr/spark-pour-les-nuls-partie-1/
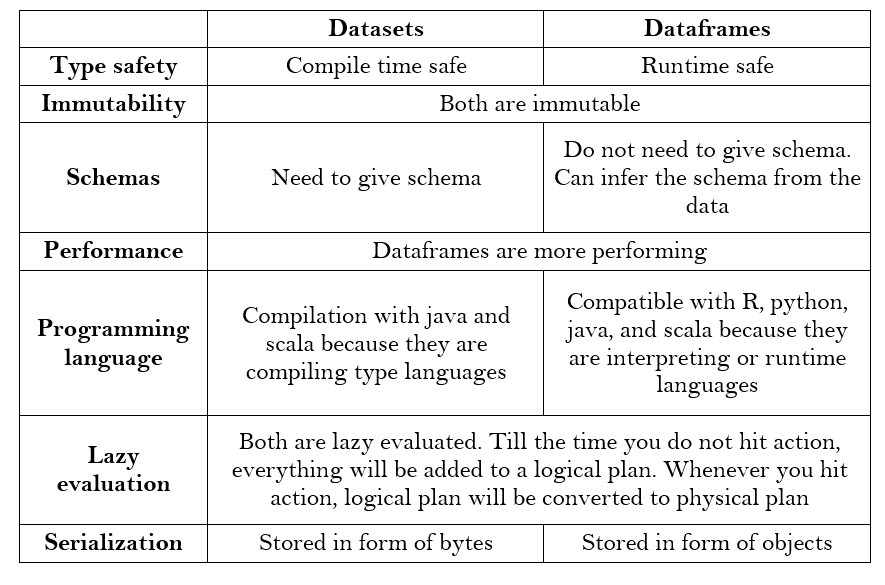
Dataframes and Datasets
Big data is classified in unstructured data, semi-structured and structured data. Apache Spark has tools for manipulating all kinds of data of those 3 types : log files, CSV files, parquet files, text files, videos, photos, etc.

Apache Spark structured API are mainly dataframes and datasets : collections defined by rows and columns, like tables.
=> Column can be an integer, a string, an array, a map or a null value,
=> Row is a record of data. A line of our data, like in SQL.
Dataframes should be familiar to you if you knows python and pandas. It gives schemas view to the data basically. A schema is composed of the name and the type of each column of our data. For Dataframes, Spark checks the type of data at the runtime of our code : that is why it is untyped API. Whereas, datasets are typed : Spark checks his type at the compile time.
Spark checks his type at the compile time : Dataframe = Dataset[Row]. Row is a generic type.
Here is a quick comparison between the two major APIs :
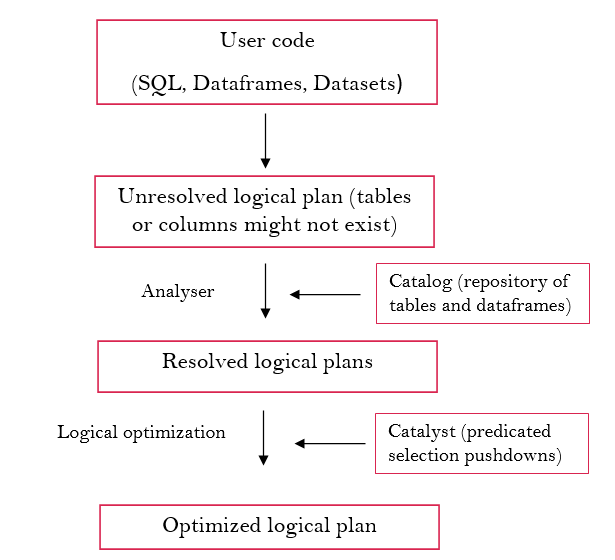
How does Spark execute structured API data flows on cluster ?
Spark follows 3 mains process to execute user’s code on the cluster. Theses steps are illustrated and explained below :
- Logical planning : do not depend on physical architecture
2. Physical planning : depends on physical architecture
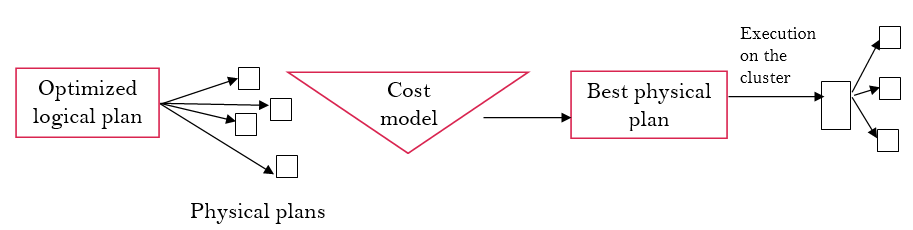
- Execution : execution of the best physical plan over RDDs.
Final resut is sent to user.
In the next article, we will go through some operations that we can do on dataframes.