Spark pour les nuls – Partie 4 – Vue d’ensemble des API Structurées de Apache Spark

Comment les données sont-elles organisées dans Apache Spark ? Quels types de données ce framework supporte ? Comment Spark exécute-t-il le code écrit sur le cluster ? Nous répondons tout simplement à ces questions dans cet article. Mais avant de nous y mettre, vous souhaiteriez peut être revoir certaines notions de bases avec Spark proposées ici : https://data-mindset.fr/spark-pour-les-nuls-partie-1/
Dataframes et Datasets
Les mégadonnées sont soit non définies, semi-structurées ou définies. Apache Spark dispose de plusieurs librairies et outils pour manipuler toutes ces catégories représentées sous forme de fichiers journaux, fichiers CSV, fichiers parquet, fichiers texte, vidéos, photos, etc.

Les API émises d’Apache Spark sont principalement des dataframes et des datasets : des collections définies par des lignes et des colonnes, comme des tables en SQL.
=> Une colonne peut être un entier, une chaîne, un tableau, une carte ou une valeur nulle,
=> Une ligne est un enregistrement de données : comme en SQL.
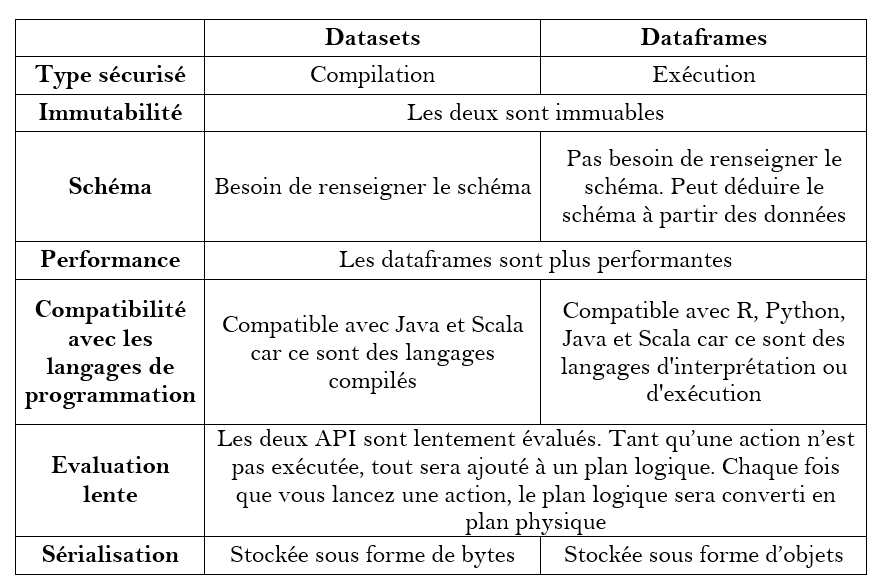
Les dataframes devaient vous être familiers si vous connaissez python et pandas. Il donne essentiellement une vue des schémas sur les données. Un schéma est composé du nom et du type de chaque colonne de nos données. Pour les dataframes, Spark accepte le type de données au moment de l’exécution de notre code : c’est pourquoi il s’agit d’une API non typée. Alors que les jeux de données (datasets) sont typés : Spark respecte son type au moment de la compilation.
Un dataframe est un ensemble de données d’objet Row : Dataframe = Dataset[Row]. Row est un type générique en Spark.
Voici une comparaison rapide entre les deux principales API :
Commentaire Spark exécute-t-il des flux de données d’API structurés sur le cluster ?
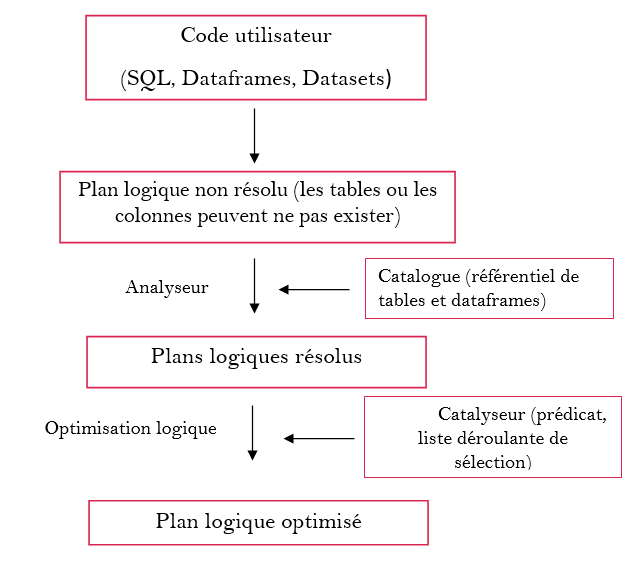
Spark suit un processus en 3 phases pour exécuter le code de l’utilisateur sur le cluster. Ces étapes sont illustrées et expliquées ci-dessous :
- La planification logique de l’exécution : elle ne dépend pas de l’architecture physique
2. La planification physique : dépend de la structure physique de l’architecture
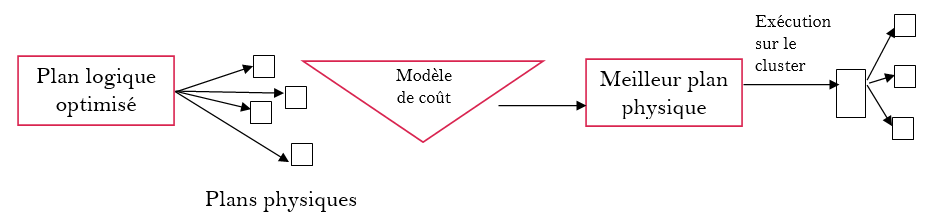
- La phase d’exécution : ici Spark exécute le meilleur plan physique sur les RDD.
Le résultat final est renvoyé à l’utilisateur sur la console ou dans un fichier.
Dans l’article suivant, nous verrons en détails différentes opérations que l’on peut effectuer sur les dataframes.