Spark - Part 5 - Basic structured operations

In this article, we are about to see some operations we can do on Dataframes. Before jumping into this, you might want to understand some basics concepts of Spark covered here: https://data-mindset.fr/spark-pour-les -nuls-partie-1/
Little reminder: Dataframes are table like collections of rows and columns, well defined. They are immutable and lazily evaluated. When we perform an action on a dataframe, we instruct Spark to perform the transformations and return the result.

Partitioning
A partition in Spark is nothing but a layout of a Dataframe or a dataset’s physical distribution across the cluster.
Let’s see an example :
//reading a csv file with schema on read
val df = spark.read.options(Map("inferSchema" -> "true", "delimiter" -> ",", "header" -> "true", "multiline" -> "true"))
.csv("C:/Users/boros/Documents/S10_Stage_Data/online-retail.csv")
// showing the number of partitions of this dataframe
println("The initial dataframe has " + df.rdd.partitions.size + " partition")
The output in our example is :
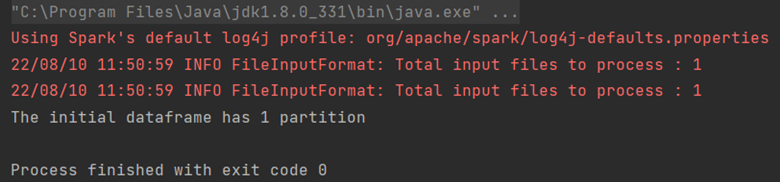
Here we have created a simple Dataframe by reading a csv file, and we print the number of partitions.
Schema
As we saw in the previous article, the schema of a Dataframe is the list of the columns names and types of this dataframe.
It can be retrieved dynamically (« schema on read »), if nothing about it is coded, but this can lead to precision issue (for example, the integer type is found instead of the long typewhile reading the data).
The schema could also be defined explicitly for untyped data sources.
.
Type = StructType (List(StructField(name, spark type, nullable)))
Here we illustrate the principle of “schema on read” with an example where the schema of a dataframe is read from a CSV file
//reading a csv file with schema on read
val df = spark.read.options(Map("inferSchema" -> "true", "delimiter" -> ",", "header" -> "true", "multiline" -> "true"))
.csv("path of your csv file")
println(df.schema)
The inferSchema parameter set to true will automatically guess the data types for each field of your CSV file.
Here the output will be :

Columns and expressions
The columns in Spark are the same as the columns in pandas. We can manipulate them with selects, removes, adds or updates as expressions.
An expression is a set of transformations on one or more values read in a dataframe.
To refer to the column type with Spark, we must import:org.apache.spark.sql.functions.col/column
Let’s list some examples of expressions:
expr (“expression”)
expr (“nomdelacolonne”) <=> col(“nomdelacolonne”)
Let’s consider the example :
expr ("nomdelacolonne” - 5) <=> col("nomdelacolonne") - 5 <=>
expr("nomdelacolonne") - 5
Here the 3 expressions are similar and have the same logical plan.
An implementation of this example is :
df.select(expr("Quantity + 5 as new_quantity")).show(3)
df.select(col("Quantity") + 5).show(3)
df.select(expr("Quantity") + 5 ).show(3)And as the logical plan is similar for these 3 expressions, the results are also similar :
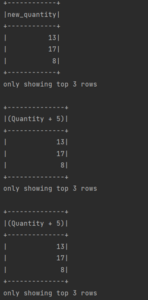
To show the columns of a Dataframe, just use the dataframe’s method columns

For example:
//reading a csv file with schema on read
val df = spark.read.options(Map("inferSchema" -> "true", "delimiter" -> ",", "header" -> "true", "multiline" -> "true"))
.csv("C:/Users/boros/Documents/S10_Stage_Data/online-retail.csv")
println(df.columns.toList)
The output will be :
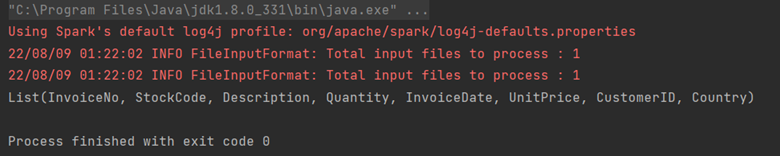
Records and Rows
Each row in a Dataframe is a single record, and inside the Spark dataframe it is an object of type Row.
The Row objects in Spark are internal representations of array to bytes.
There are many ways to select rows of a Dataframe based on conditions, using :
- The filter method:
- //reading a csv file with schema on read
val df = spark.read.options(Map("inferSchema" -> "true", "delimiter" -> ",", "header" -> "true", "multiline" -> "true"))
.csv("C:/Users/Documents/online-retail.csv")
//filter
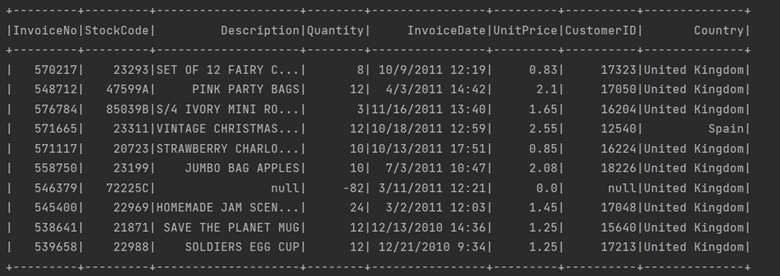
df.filter(col("country") === "USA").show()
Then the corresponding output will be :
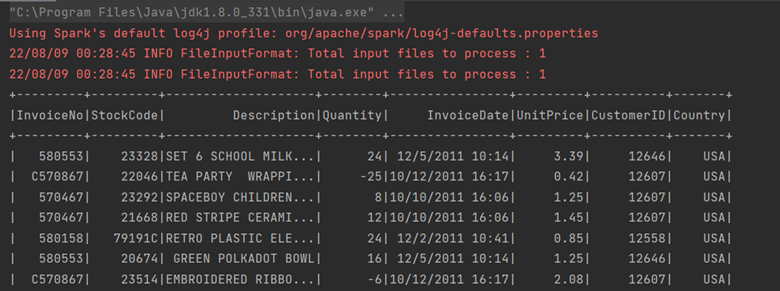
- The where method :
//reading a csv file with schema on read
val df = spark.read.options(Map("inferSchema" -> "true", "delimiter" -> ",", "header" -> "true", "multiline" -> "true"))
.csv("C:/Users/Documents/online-retail.csv")
//where
df.where(col("country") === "USA").show()Then the corresponding output will be :
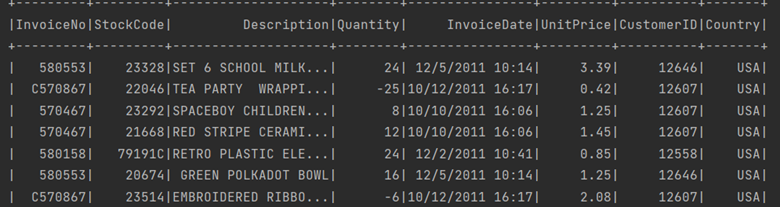
To show the first row of a Dataframe, just use the first method :
//reading a csv file with schema on read
val df = spark.read.options(Map("inferSchema" -> "true", "delimiter" -> ",", "header" -> "true", "multiline" -> "true"))
.csv("C:/Users/Documents/online-retail.csv")
println(df.first())
Then the corresponding output will be :

To create a row in your code, just instantiate a Row object with:
Row (value1, value2, … , valuen)
Note that the parameters must be in the same order as the schema of the dataframe.
In the example below we create a dataframe containing some US towns from scratch:
val schema = StructType(Array(StructField("Ville", StringType, true), StructField (name="Pays", StringType, true)))
val rows = Seq(Row ("Los Angeles", "United States"), Row ("New York", "United States"), Row ("London", "United Kingdom"))
val parallelizeRows = spark.sparkContext.parallelize(rows)
val df = spark.createDataFrame(parallelizeRows, schema)
df.show()
The output will be:
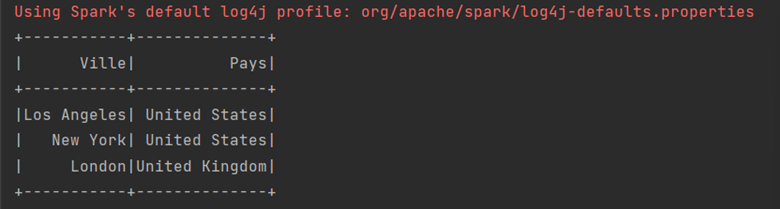
Select and Select Expr
To select a column, we can :
– use the column name directly
– use the column name inside an expression: this way leads to transformations inside the expr method.
Below is an example with both selection ways :
reading a csv file with schema on read
val df = spark.read.options(Map("inferSchema" -> "true", "delimiter" -> ",", "header" -> "true", "multiline" -> "true"))
.csv("C:/Users/Documents/online-retail.csv")
df.select("Description").show(5)
df.select(expr("Description as desc")).show(5)
The output will be:
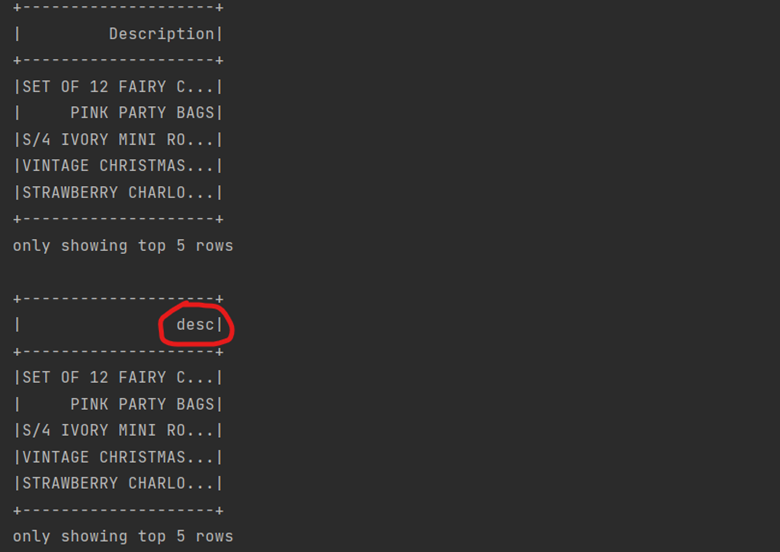
Limit
The limit methode is useful when we need to extract a part of the Dataframe before doing something costly.
Typically, we just want the top 5, 10 or 100 results from the data.
As an example, we will use the previous Dataframe and apply a limit of 10
//reading a csv file with schema on read
val df = spark.read.options(Map("inferSchema" -> "true", "delimiter" -> ",", "header" -> "true", "multiline" -> "true"))
.csv("C:/Users/Documents/online-retail.csv")
df.select("Description").show(5)
df.select(expr("Description as desc")).show(5)
println(df.limit(10).show())
The corresponding output will be:
Repartition and coalesce
The repartition method can be used to increase the number of partitions in a Dataframe.
It divides the data equally across the cluster, but a shuffle is necessary.
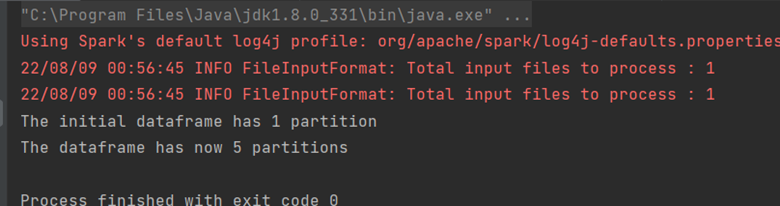
Let’s see an example with the firstDataframe we have created that had one partition.
//reading a csv file with schema on read
val df = spark.read.options(Map("inferSchema" -> "true", "delimiter" -> ",", "header" -> "true", "multiline" -> "true"))
.csv("C:/Users/Documents/online-retail.csv")
// showing the number of partitions of this dataframe
println("The initial dataframe has " + df.rdd.partitions.size + " partition")
//increasing the number of partitions
val df1 = df.repartition(5)
println("The dataframe has now " + df1.rdd.partitions.size + " partitions")
The corresponding output will be:
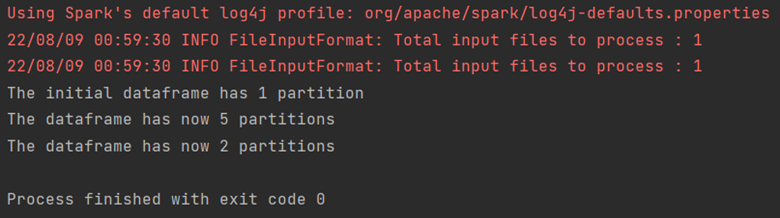
On the other hand, the coalesce method reduces the number of partitions in the Dataframe.
It avoids a shuffle, but the data will not be divided equally across the Spark cluster, and this can lead to a data skew. For this reason, it is important to analyze the data and the need before using repartition or coalesce.
val df2 = df1.coalesce(2)
println("The dataframe has now " + df2.rdd.partitions.size + " partitions")
the corresponding output will be:
To summarize:
| “Shuffle” | Possible “Data Skew” | |
| Repartition | Yes | No |
| Coalesce | No | Yes |
Collecting rows to the driver
We can retrieve the data from a Dataframe, with the collect method.
Be careful : this collects the entire Dataframe and can crash the Spark Driver if the Dataframe is too large.
Generally, we will need to collect only n rows from a dataframe with the take method.
As an example:
//reading a csv file with schema on read
val df = spark.read.options(Map("inferSchema" -> "true", "delimiter" -> ",", "header" -> "true", "multiline" -> "true"))
.csv("C:/Users/Documents/online-retail.csv")
println(df.collect().toList.take(2))
The output will be:

If you want to collect partitions one by one on the Driver, use the toLocalIterator method.
This method can also crash the Driver Spark if the partitions are very large. What is more, this can take much time because Spark computes the partitions one by one … not in parallel..
Vous avez maintenant plusieurs astuces pour commencer à travailler sur les Dataframes avec Spark. Bien sûr, nous n’avons pas couvert l’ensemble des méthodes existantes, mais cet aperçu est assez bon au début. . Dans le prochain article, nous verrons comment travailler avec les différents types de framework Apache Spark.



