TensorFlow -Partie 2 – Classification d’images

Introduction
Les techniques d’apprentissage automatique sont des techniques très utilisées et ayant montré leur efficacité dans le domaine de l’intelligence artificielle. Pour les utiliser, plusieurs bibliothèques ont été mises à disposition des développeurs constituant une boite à outils permettant leur exploitation efficace, et ce, dans plusieurs langages de programmation tels que R, Python, matlab, …
Dans cet article, nous évoquerons l’un des aspects de l’apprentissage automatique en implémentant un modèle de classification d’images de vêtements selon leur type (t-shirt, pantalon, …) en utilisant la bibliothèque TensorFlow de Python qui constitue l’une des principales offres de machine learning open source.
Environnement de travail
Dans cet article, nous utilisons l’environnement Jupyter Notebook sous Anaconda. Si vous ne l’avez pas encore effectué, il est temps de le faire !
C’est parti
- Lancer Anaconda Navigator depuis le menu initial
- Cliquer sur l’option Installer l’outil Jupyter Notebook
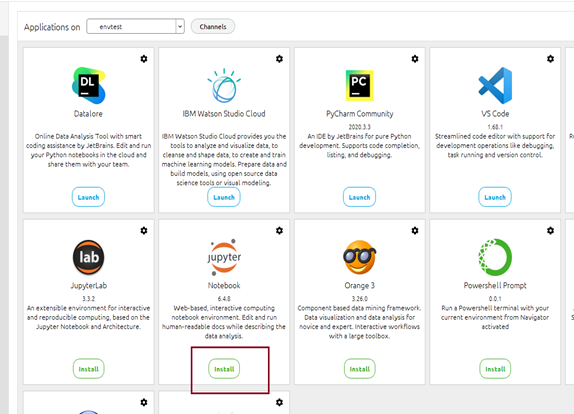
3. Une fois le logiciel installé, vous pouvez le lancer depuis Anaconda Navigator en cliquant sur l’option Launch. Cette option sera disponible lorsque l’installation sera terminée.
Classification des images avec TensorFlow
Le jeu de données
TensorFlow vient (entre autres) avec une bibliothèque d’images fournie par Zalendo et présente 10 types de vêtements et accessoires (t-shirt, valise …). Tout d’abord, notre tâche consiste à entraîner le modèle pour qu’il apprenne à reconnaître ce que représente chaque image, à savoir la classe à laquelle elle appartient. Une fois ce modèle entraîné, il doit être capable de prédire la classe à laquelle appartient toute nouvelle photo fournie.
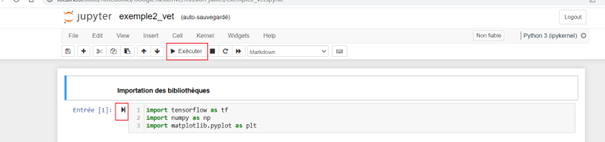
Commençons par importer les bibliothèques nécessaires
Pour exécuter le code de chaque cellules vous pouvez:
Soit choisir l’option Exécuter
Soit cliquer sur la flèche à côté de la cellule comme le montre la figure ci-dessous.
Chargeons maintenant le dataset : notre dataset présente 60 000 images pour l’entraînement et
10 000 pour le test.

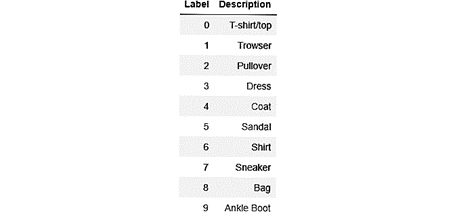
Train_images : est un tableau contenant les 60 000 images à basse résolution (28*28)
Train_labels : est un tableau contenant les 60 000 étiquettes associées aux différentes images. Les labels désignent les différentes catégories et ils sont représentés par les valeurs allant de 0 jusqu’à 9.
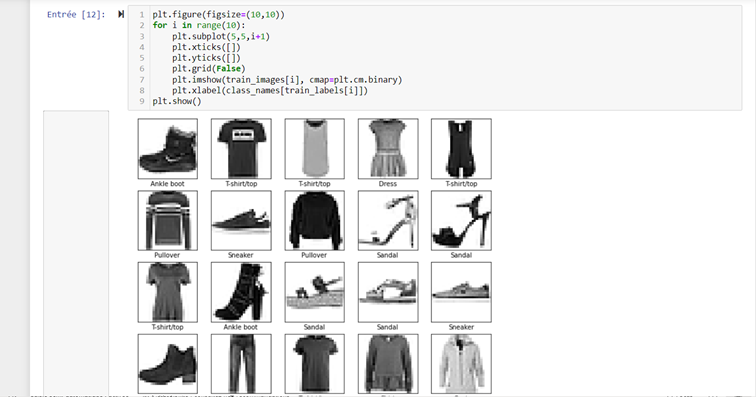
Pour vérifier le bon téléchargement de la data, nous allons afficher les dix premières images en exécutant ce code :
Créons nos 10 cours :

Avant de commencer la création de notre modèle, une phase de normalisation des pixels doit être faite pour avoir des valeurs entre 0 et 1

Ici nous allons commencer à créer notre modèle avec TensorFlow et Keras. Ensemble, ces deux bibliothèques donnent de bons résultats dans le domaine de la classification (et de l’apprentissage profond en général).
Nous allons créer un modèle simple composé de trois canapés : une couche d’entrée, une couche cachée et une couche de sortie.

Pour être sûr qu’il n’y avait pas d’erreur lors de la création du modèle, vous pouvez tester cette instruction et le résultat sera le suivant :
Il faut maintenant compiler le modèle. Dans cette phase, il faut choisir la méthode d’optimisation, une fonction de perte et une fonction de mesure de précision.
Ces choix sont aussi importants que le choix de l’architecture du réseau. La méthode d’optimisation influence la vitesse d’entraînement du réseau et les deux autres paramètres permettent d’évaluer les performances de notre modèle.

Nous pouvons maintenant commencer l’entraînement de notre modèle avec la fonction fit :
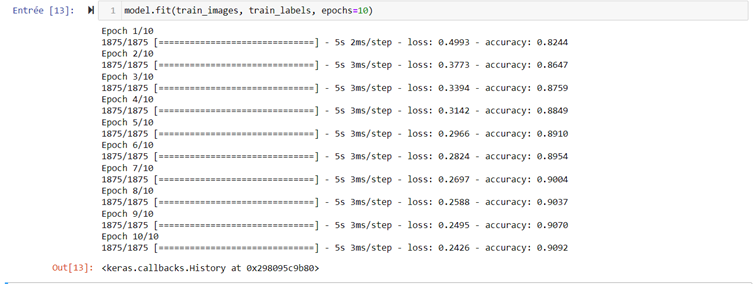
Maintenant, notre modèle est entraîné avec un taux de précision de 90 %. Nous allons l’appliquer sur la base de test fournie par TensorFlow :

Nous prenons une image aléatoire de la base de test pour voir si notre modèle va le classer correctement :
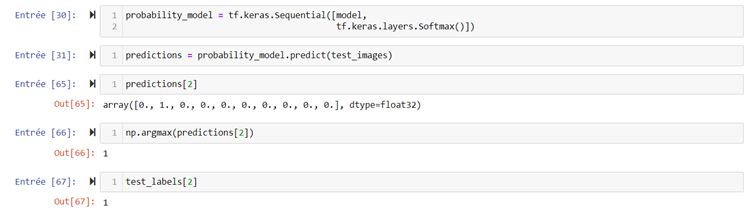
Comme nous pouvons le constater, le modèle a prédit que l’image appartient à la classe 1 (voir Entrée [65]) et correspond à la vraie classe à laquelle appartient l’image (voir Entrée [67]).
Avec cette base sur un taux de précision de 88%. Bien que ce résultat soit acceptable, nous pouvons quand même l’améliorer et réduire le taux d’erreur en utilisant d’autres techniques plus puissantes.
Nous avons dans cet article développé un classificateur d’images avec les techniques d’apprentissage approfondies en utilisant les bibliothèques TensorFlow et Keras de Python.
Ces techniques ont fait leurs preuves pour la résolution de plusieurs types de problèmes tels que la détection d’anomalies, la régression, la classification, la reconnaissance faciale, …
L’apprentissage profond et les réseaux de neurones font l’objet de notre prochain article.


