Spark for dummies - Part 2 - Architecture
In the previous article we gave a general introduction to Spark and how to install it.
In this article, we will cover all the different parts of the Spark architecture, terminology and concept to understand for the future. Alors continuons.

Architecture de base
A single computer does not have enough power to perform certain resource-intensive tasks. In this case, a group of machines called a cluster is used which will centralize the power of each of the machines and manage it between the different tasks to be performed. That’s kind of the role that Spark plays. It orchestrates all the tasks between the different computers of a cluster and for this, a resource manager is used in the Spark architecture to do this work: YARN or Mesos.
Applications
Spark applications consist of a parent process (the driver) which is responsible for executing commands at executor level to complete a given task. Executors mostly run spark code. The driver can be launched from several Spark API languages.
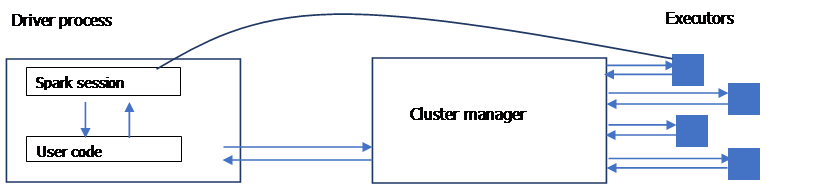
Language APIs
Spark’s language APIs allow programming on Spark with any language that will then be translated into code that can be executed by JVM runners
Spark session
As we saw above, we control our spark applications from a process driver which represents a spark session.
Launch a session locally
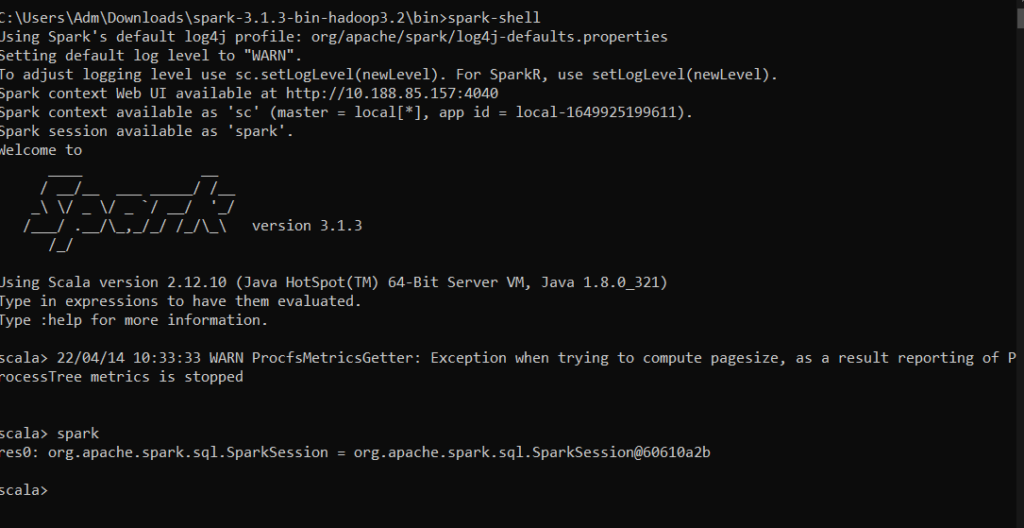
To launch a session with spark installed locally, go to the bin directory of Spark and type the command : spark-shell
You should have the following output :
Launching a spark session from IntelliJ in a scala project
To do this, follow the steps below to create the project and the session:
- Go to File -> New -> Project : you will have a new window to create your project
- Select Scala and sbt and click on the Next button
- Give a name to your project and check the project directory to be where you want it to be
- Then choose the JDK (8 or 11 ideally); if it is not installed, you can download it the same time
- After that, click on finish
You then have a new Scala project.
In the src/main/scala directory of your project, create a new Scala class and select object and give a name to the object.
You now should have this in the structure of your project :
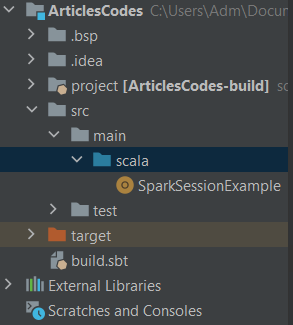
I named my Scala class SparkSessionExample, you can named it the way you want.
- Open the build.sbt file and add these lines to add the spark dependencies for our project :

- – Now we will create a new Spark session in our class and have the same output as in the console :

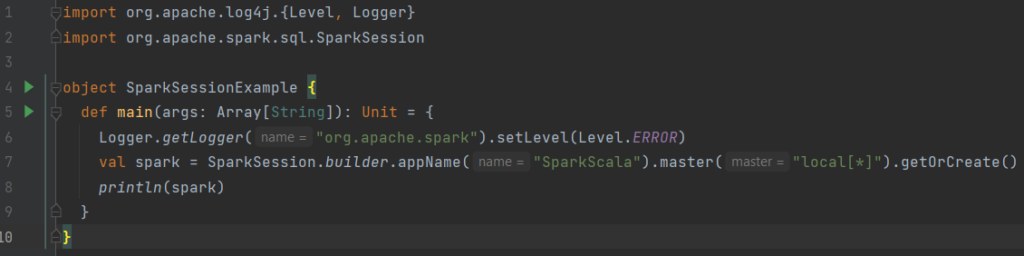
No worries, I will explain every part of this code :
- To create your SparkSession in Scala, as shown, you need to use the builder method
- master() : if you are running it on the cluster you need to use your master name as an argument to the master() function. Usually it would be either yarn or mesos depends on your cluster setup.
- Here we use local[x] for standalone mode. The parameter x should be an integer value and should be greater than 0. It represents the number ofworker threads, ideally set of the number of logical cores on your machine. We will explain all these concepts below.
- The appName() function is used to set our application name
- getOrCreate() function returns a SparkSession object if already exists, creates new one if not exists.
- Line 6 of the code is just to remove all the logs that are displayed on the console when running the object
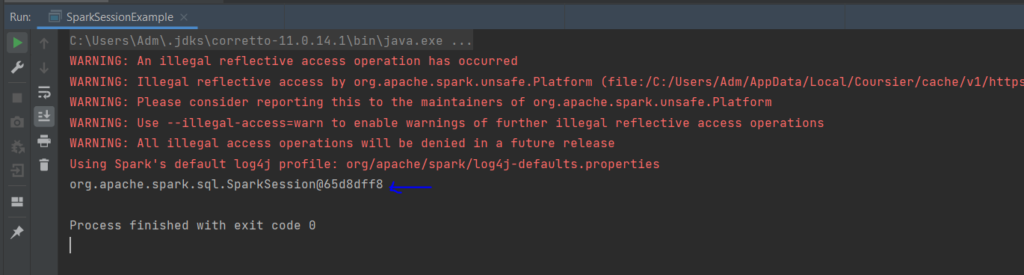
To run this, you can click on the run icon just on the Line 5 of your code.
You should obtain this output : it displays the active SparkSession.
Now that we have our spark session running, let’s do a simple creation of range of number :
Locally

With IntelliJ
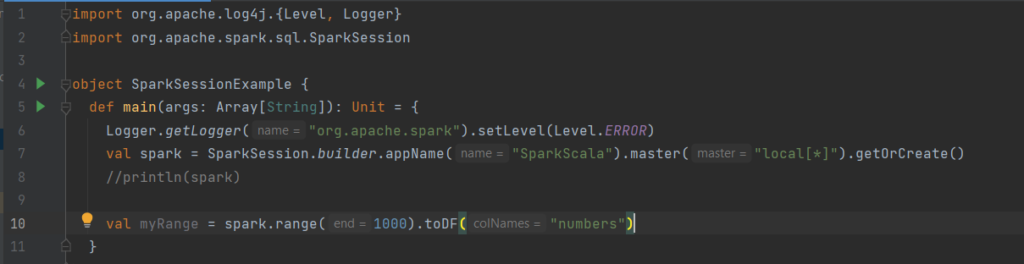
What we do there is that we created a dataframe named myRange with 1 column named number and 1000 rows with values from 0 to 999. This dataframe is distributed. When run on a cluster, each part of this range of numbers exists on different executors.
Dataframes
This is the most common structured API in Spark. It is a data table with rows and columns. Dataframes in python and R are not distributed. They are on a single computer. But with spark, it’s easy to convert them into spark as distributed dataframes. A schema in a dataframe is the definition of columns and types of this dataframe.
Note : There are several illustrations of distributed collections with Spark: Datasets, dataframes, sql tables, rdd. The easier and more efficient one are dataframes, available in all languages.
Partitions
A partition in Spark is chunks of data or a collection of rows on one physical machine of the cluster.
Note : We don’t have to manipulate partitions directly in Spark, we just specified the transformations we want to do on our dataframes, and Spark itself manage the execution on the cluster.
Transformations
A transformation is an instruction to modify a dataframe. Let’s do a transformation on the dataframe we created to see the result.
Locally

With IntelliJ

As you can see it, we don’t have any output. Spark will not show any output until it call an action.
Note: There are differents types of transformations.
- Narrow transformations : is about 1 input partition that gives 1 output partition (pipeline operation in memory)
- Wide transformations : is about n partitions => n partitions (shuffle)
Lazy evaluation
Spark builds up a plan of transformations that will be made on the dataframe and waits the very last moment to execute it. That optimizes the entire dataflow from end to end.
Ex: predicate pushdown : by putting the filter transformation of a dataframe at the end of all the operation automatically. (less rows are then processed)
Actions
It is an operation that instructs Spark to compute the result from a series of transformations. From our example with the evenNumbers dataframe, a simple action could be count to output the numbers of even rows in the myRange dataframe.
Locally
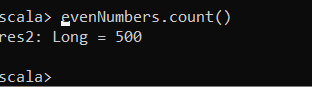
With IntelliJ

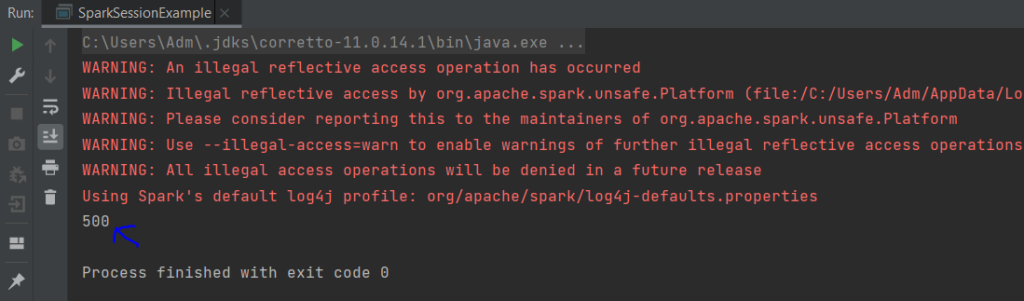
Note: There are 3 kinds of actions in Spark :
- View data in the console
- Collect data to native objects in the respective language
- Write to ouptut data sources
Spark UI
It is a tool included in Spark that one can inspect to monitor jobs running on the cluster. It is available on port 4040 of the driver node. It will be on localhost if you installed Spark locally.
So let’s check the http://localhost:4040
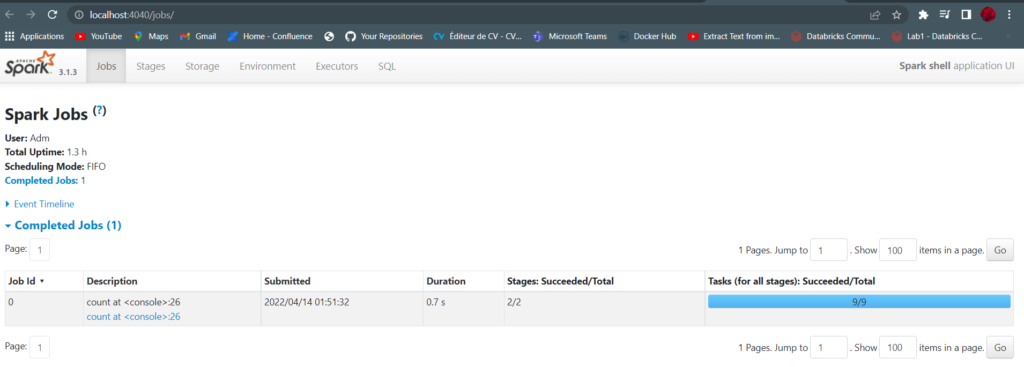
Note: A Spark job is a set of transformations triggered by an action that you can monitor from the Spark UI.
An end to end example

We will use the IntelliJ installation.
In this example, we will use a dataset from kaggle on people reading habits. Here is the link to download the csv file : https://www.kaggle.com/datasets/vipulgote4/reading-habit-dataset
We will load the csv file in a dataframe and made some manipulations on it.
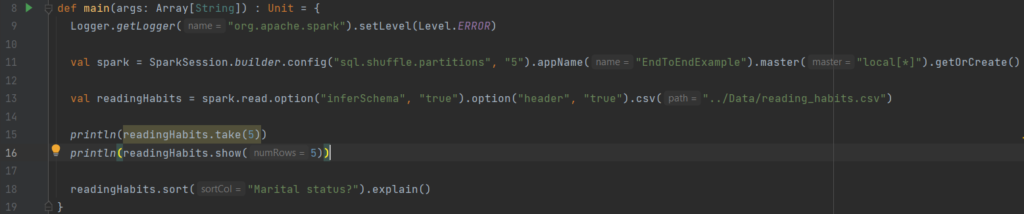
Let’s comment each line of the code :
Line 13
What we did here is to use a DataFrameReader that is associated with our session to read the csv file in a dataframe named readingHabits.
Read is a transformation => Spark peeks a couple of rows he find the schema
We also specify some options like :
- Schema inference : we want Spark to take a best guess at what the schema of our dataframe should be
- Header : to specify that the first row is the header in the file
Line 15
Take the first 5 lines of our dataframe and returns it as an array
Line 18
The sort function is a transformation that don’t modify our dataframe but returns a new dataframe with the condition
The explain function display us the plan of execution of the code
The number of default shuffle partitions is 200, it can be changed with spark.conf.set(‘spark.sql.shuffle.partitions’, ‘5’) (line 11)
Spark knows how to recalculate any partition by performing operations on the same input or output data: this is the heart of the functional programming model.
Dataframes and SQL
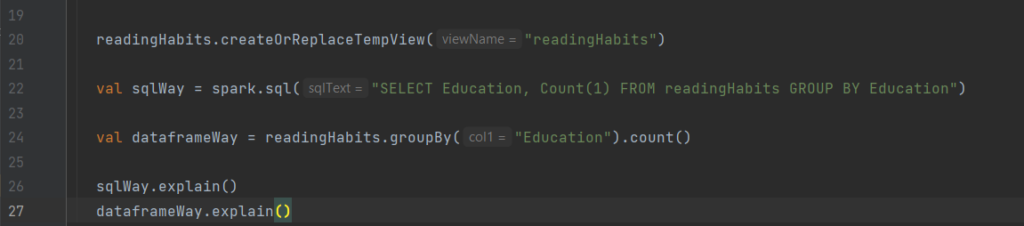
Spark can run the same transformations with SQL, so we can express our logic in SQL or dataframes ans Spark will compile it to an underlying plan before executing it. SQL can register Dataframe as a table or a view : query with SQL createOrReplaceTempView
Lines 22 and 24 show that the sql query and it equivalent by using dataframe has the same explain plans.
Conclusion
In this article we see the basics of Spark architecture. We learn many concepts about dataframes, partitions, actions, transformations, lazy evaluation, and the equivalence SQL and the other language for dataframe In the next article, we will see deeply Spark’s toolset.




