Spark pour les nuls – Partie 2 – Architecture
Dans l’article précédent, nous avons fait une introduction générale à Spark et comment l’installer.
Dans cet article, nous couvrirons toutes les différentes parties de l’architecture, de la terminologie et du concept de Spark à comprendre pour l’avenir. Alors continue.

Architecture de Spark
Un seul ordinateur n’a pas assez de puissance pour effectuer certaines tâches qui fourniront de grandes ressources. Dans ce cas, on fait appel à un groupe de machines appelé cluster qui va centraliser la puissance de chacune des machines et la gérer entre les différentes tâches à effectuer. C’est un peu le rôle que joue Spark. Il orchestre toutes les tâches entre les différents ordinateurs d’un cluster et pour cela, un gestionnaire de ressources est utilisé dans l’architecture de Spark pour faire ce travail : YARN ou Mesos.
Applications
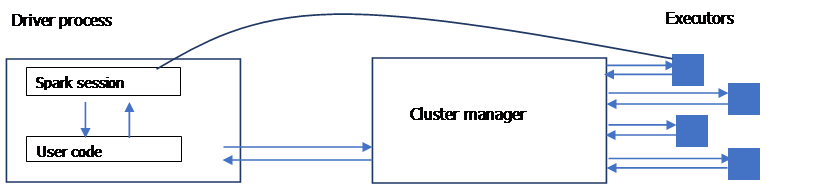
Les applications spark consistent dans un processus parent (le pilote) qui est responsable d’exécuter les commandes au niveau des exécuteurs pour compléter une tâche donnée.
Les exécuteurs pour la plupart du temps exécutent du code spark. Le pilote peut être lancé à partir de plusieurs langages des API Spark.
Les API de langage
L’API de langage de Spark permet de programmer sur Spark avec n’importe quel langage qui sera ensuite traduit en code pouvant être exécuté par les exécuteurs JVM
Étincelle de session
Comme nous l’avons vu plus haut, nous contrôlons nos applications Spark à partir d’un pilote de processus qui représente une session Spark.
Lancer une session Spark localement
Pour lancer une session avec Spark installé localement, allez dans le répertoire bin de Spark et entrez la commande : spark-shell
Vous devriez avoir le résultat suivant :
Lancer une session Spark à partir d’un projet scala dans IntelliJ
Pour ce faire, suivez les étapes ci-dessous pour créer le projet et la session :
- Ouvrir File -> New -> Project : une nouvelle fenêtre s’affiche pour créer le projet
- Choisir Scala et SBT et cliquer sur Suivant
- Donner le nom que vous voulez au projet et vérifier que le dossier de sauvegarde est le bon
- Maintenant choisir le JDK installé (version 8 ou 11 de préférence), vous pouvez choisir la version et le télécharger au même moment si ce n’était pas déjà fait
- Après cela cliquer sur Finish
Vous venez de créer un projet scala.
Dans le dossier src/main/scala de votre projet, créez une nouvelle classe Scala, sélectionnez le type object et donnez un nom à votre classe.
Vous devriez avoir quelque chose choisi du genre dans la structure de votre projet :
Dans cet exemple, j’ai nommé ma classe SparkSessionExample , vous pouvez nommer votre classe comme vous voulez.
- Ouvrir le fichier build.sbt puis rajouter cette ligne qui représente la librairie de spark nécessaire pour le projet :

- Nous allons maintenant créer une nouvelle session Spark dans notre classe et avoir la même sortie que dans la console :

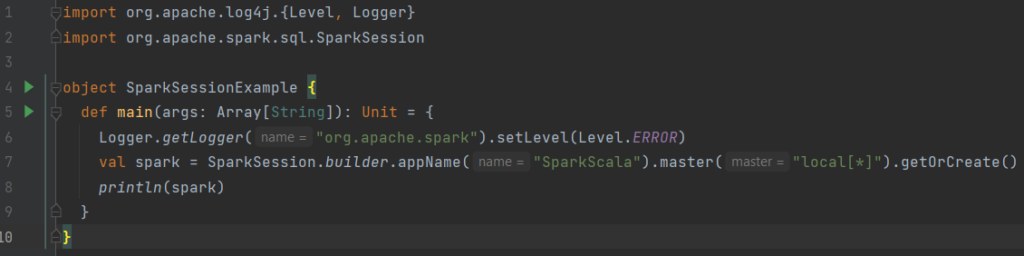
Pas d’inquiétude, je vais vous expliquer chaque partie de ce code :
- Pour créer votre session Spark dans Scala, comme indiqué, vous devez utiliser la méthode builder
- master() : normalement, il s’agirait de Yarn ou de mésos en fonction de la configuration de votre cluster.
- Ici, nous utilisons local[x] pour le mode autonome. Le paramètre x doit être une valeur entière et doit être supérieur à 0. Il représente le nombre de files d’exécution en tant qu’exécuteurs en local, idéalement le nombre de coeurs de votre machine. Nous allons expliquer tous ces concepts ci-dessous.
- La fonction appName() est utilisée pour définir le nom de notre application
- La fonction getOrCreate() renvoie un objet SparkSession s’il existe déjà, en crée un nouveau s’il n’existe pas.
- La ligne 6 du code sert juste à supprimer tous les logs qui s’affichent sur la console lors de l’exécution de l’objet
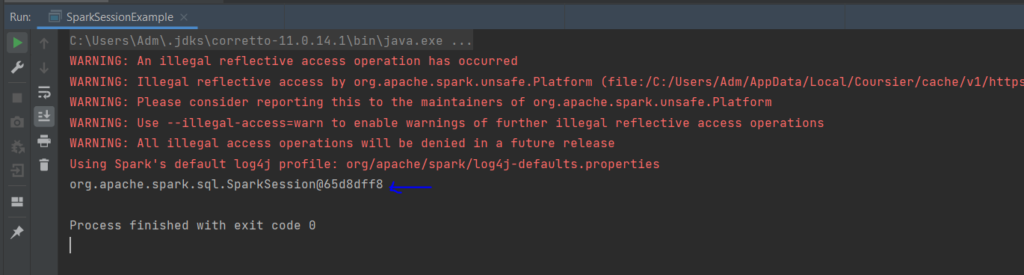
Pour l’exécuter, vous pouvez cliquer sur l’icône d’exécution juste sur la ligne 5 de votre code.
Vous devriez obtenir cette sortie : elle affiche la session Spark active.
Maintenant que nous avons réussi à créer notre session Spark, essayons un code basique de création d’un tableau d’entiers.
En local

Avec IntelliJ
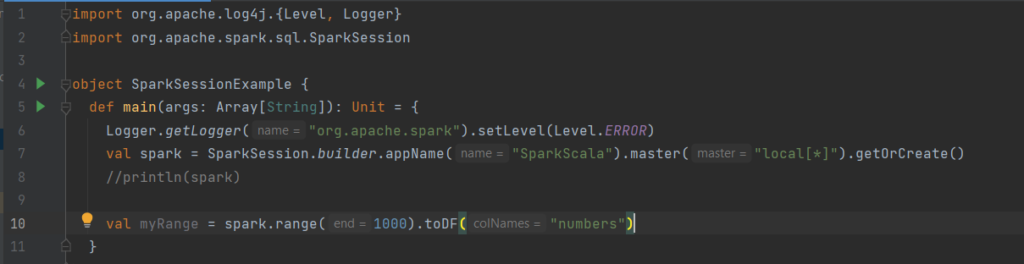
Ce que nous faisons ici, c’est que nous avons créé un dataframe nommé myRange avec une colonne nommée numbers et 1000 lignes avec des valeurs de 0 à 999. Ce dataframe est distribué. Lorsqu’il est exécuté sur un cluster, chaque partie de cette plage de nombres existe sur différents exécuteurs.
Trames de données
Il s’agit de l’API émise la plus courante dans Spark. C’est un tableau de données avec des lignes et des colonnes. Les dataframes en python et R ne sont pas distribués. Ils sont sur un seul ordinateur. Mais avec Spark, il est facile de les convertir en dataframes distribués. Un schéma dans un dataframe est la définition des colonnes et des types de ce dataframe.
Note : Il existe plusieurs illustrations de collections distribuées avec Spark : Datasets, dataframes, sql tables, rdd. Les plus simples et les plus efficaces sont les dataframes, disponibles dans tous les langages de programmation dans Spark.
Cloisons
Une partition dans Spark est constituée de blocs de données ou d’un ensemble de lignes sur une machine physique du cluster.
Note : Nous n’avons pas besoin de manipuler les partitions directement dans Spark. En spécifiant les transformations que nous voulons faire sur nos dataframes, Spark lui-même gère l’exécution sur le cluster.
Transformations
Une transformation est une instruction pour modifier une trame de données. Faisons une transformation sur le dataframe que nous avons créé pour voir le résultat.
Local

Avec IntelliJ

Comme vous pouvez le voir, nous n’avons aucune sortie. Spark n’affichera aucune sortie tant qu’il n’aura pas appelé une action.
Remarque : Il existe différents types de transformations.
- Transformations étroites : c’est environ 1 partition d’entrée qui donne 1 partition de sortie (opération de pipeline en mémoire)
- Transformations grandes : concernent n partitions => n partitions (shuffle)
Évaluation paresseuse
Lorsqu’on lance des transformations en Spark, elles ne sont pas exécutées directement ; Spark a intégré un plan d’exécutions qui sera fait sur la dataframe et attendra le tout dernier moment pour l’exécuter. Cela optimise l’ensemble du flux de données de bout en bout.
Ex : pushdown : en faisant automatiquement la transformation « filter » d’une dataframe à la fin de toute l’opération. (moins de lignes sont pensés alors)
Actions
C’est une opération qui demande à Spark de calculer le résultat d’une série de transformations. À partir de notre exemple avec la trame de données evenNumbers , une simple action peut être comptée pour afficher le nombre de lignes paires dans la trame de données myRange .
Local
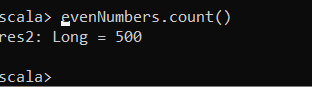
Avec IntelliJ

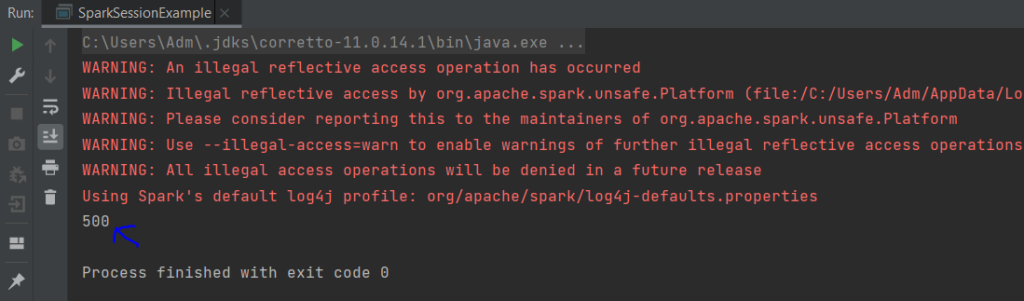
Remarque : Il y a trois types d’actions en Spark :
- Afficher les données dans la console
- Collecter les données dans des objets propres au langage donné
- Écrire sur les sources de données de sortie
Interface utilisateur Spark
Il s’agit d’un outil inclus dans Spark que l’on peut inspecter pour surveiller les jobs effectués sur le cluster. Il est disponible sur le port 4040 du nœud du pilote. Ce sera sur localhost si vous avez installé Spark localement.
En allant sur http://localhost:4040
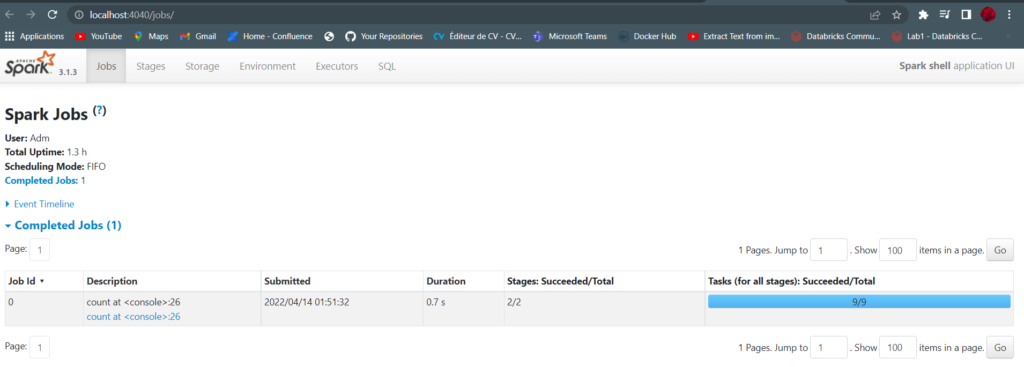
Remarque : Une tâche (tâche) Spark est un ensemble de transformations déclenchées par une action que vous pouvez surveiller à partir de l’interface utilisateur Spark.
Un exemple de bout en bout

Pour cet exemple et la suite des articles, nous allons utiliser l’IDE IntelliJ.
Dans cet exemple, nous allons utiliser un dataset de routines de lecture disponible sur le lien suivant : https://www.kaggle.com/datasets/vipulgote4/reading-habit-dataset
Nous allons charger le csv et faire quelques tests avec le dataset :
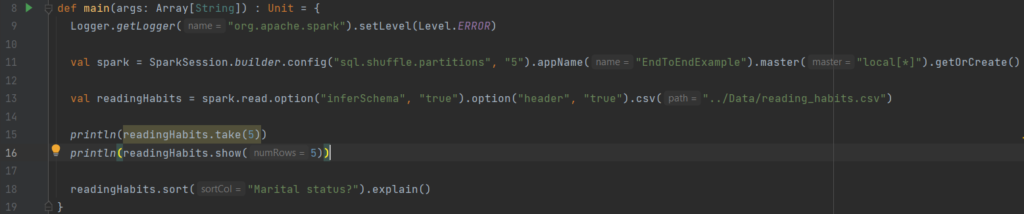
Commentons chaque ligne de code :
Ligne 13
Ce que nous avons fait ici est d’utiliser un DataFrameReader associé à notre session pour lire le fichier csv dans un dataframe nommé readingHabits .
Lire est une transformation => Spark jetez un coup d’œil sur quelques lignes de notre fichier pour retrouver le schéma du dataframe
Nous spécifions également certaines options comme :
– Inférence de schéma : nous voulons que Spark devine au mieux ce que devrait être le schéma de notre dataframe
– Header : pour spécifiques que la première ligne est l’entête du fichier
Ligne 15
La fonction take() récupère ici les 5 premières lignes de notre dataframe et les retourne sous forme de tableau
Ligne 18
La fonction sort() est une transformation qui ne modifie pas notre dataframe mais renvoie une nouvelle dataframe avec la condition
La fonction explique() nous affiche le plan d’exécution du code
Le nombre de partitions aléatoires par défaut est de 200, il peut être modifié comme suit : spark.conf.set(‘spark.sql.shuffle.partitions’, ‘5’) (ligne 11)
Spark sait recalculer n’importe quelle partition en effectuant des opérations sur les mêmes données d’entrée ou de sortie : c’est le cœur du modèle de programmation fonctionnel.
Dataframes et SQL
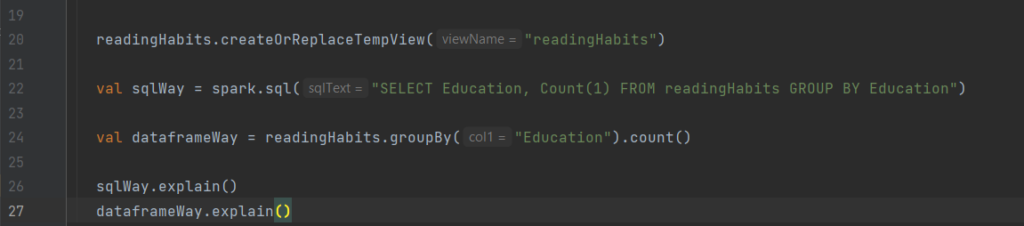
Spark peut effectuer les mêmes transformations avec SQL, nous pouvons donc exprimer nos requêtes en SQL ou avec des dataframes et Spark la compilera dans un plan sous-jacent avant de l’exécuter. SQL peut enregistrer une dataframe en tant que table ou vue : requête avec SQL createOrReplaceTempView
Les lignes 22 et 24 montrent que la requête SQL et son équivalent en utilisant dataframe ont les mêmes plans d’exécution .
Conclusion
Dans cet article, nous avons vu les bases de l’architecture Spark, de nombreux concepts sur les dataframes, les partitions, les actions, les transformations, la lazy evaluation et l’équivalence SQL et les autres langages pour les dataframe. Dans le prochain article, nous verrons en profondeur l’ensemble d’outils de Spark.




